
Pandas ile çalışıyorsanız, büyük veri setleriyle karşılaştığınızda pek çok zorlukla karşılaşmış olabilirsiniz. Küçük veri setleri üzerinde oldukça etkili olan süreçleriniz, geniş veri kümelerinde yavaşlayabilir. Bir zamanlar saniyeler içinde tamamlanan bir script, şimdi dakikalarca sürmektedir.
Bu durumda atacağınız adımlar oldukça tahmin edilebilir ve genellikle can sıkıcıdır. Verilerinizi küçültmek zorunda kalabilir, parça parça işlemek için mantığınızı yeniden yazabilir veya tüm sürecinizi Spark gibi dağıtık bir çerçeveye taşımak zorunda kalabilirsiniz.
Peki, bu duvarı sadece bir bayrakla aşabileceğinizi söylesek? Bugün, **NVIDIA cuDF** adındaki, GPU hızlandırmalı bir DataFrame kütüphanesinin yardımıyla işlerinizi nasıl hızlandırabileceğinizi keşfedeceğiz. Mevcut iş akışlarınızı yeniden yazmadan, GPU kullanımını etkin hale getirerek bu işlemleri hızlandırmak mümkün.
Hisse Senedi Fiyatlarını Zaman Tabanlı Pencerelerle Analiz Etme
Finansal analizde sıkça karşılaşılan bir görev, büyük, zaman serisi veri setlerinde trendleri keşfetmektir. Bu genellikle groupby().agg() gibi pandas işlemleri ve yeni tarih özellikleri oluşturmayı içerir.
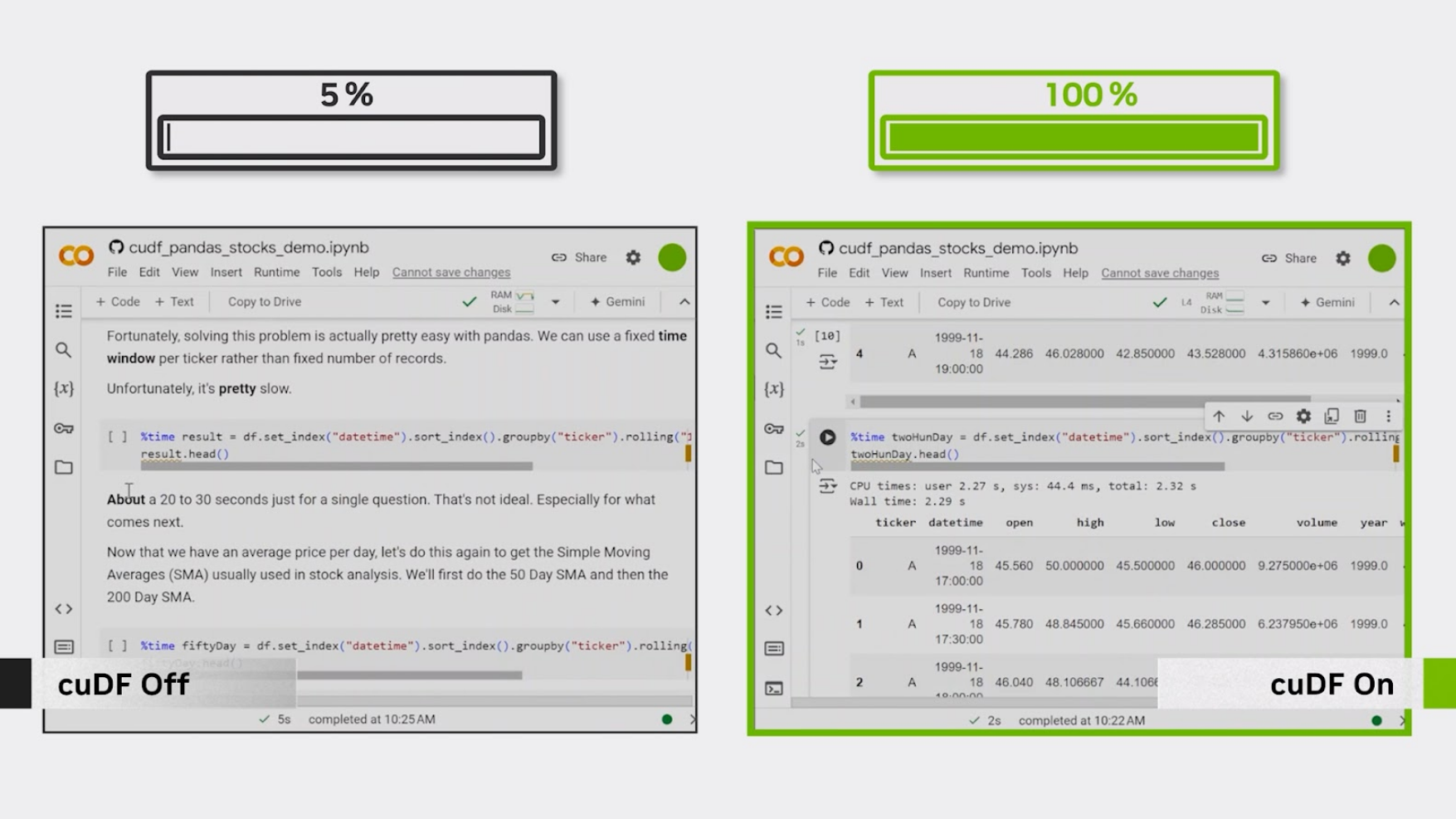
Gerçek engel, genellikle bir zaman diliminde metrikleri hesaplamak için yapılan işlemlerde ortaya çıkar. CPU’da groupby().rolling() ile ’50 Günlük’ veya ‘200 Günlük’ Basit Hareketli Ortalamaları hesaplamak oldukça yavaş olabilir. Ancak, GPU hızlandırması ile bu işlemler, 20 katı kadar daha hızlı sonuçlar verebilir. Yani, dakikalarca süren bir işlem, saniyeler içinde tamamlanabilir.
Bu farkı görmek için aşağıdaki videoyu izleyin:
Kodun tamamını Colab veya GitHub üzerinde keşfedin.
Büyük Metin Alanları ile İş İlanlarını Analiz Etme
İş zekası, genellikle metin açısından yoğun veri analizi gerektirir ve bu durum pandas ile büyük bir zorluk oluşturur. Büyük string kolonları muazzam miktarda bellek tüketir – bu çalışma için yüklenen dosya 8GB’tır – ve standart işlemler son derece yavaş ilerler.
Dosya okuma (read_csv), string uzunluğu hesaplama (.str.len()) ve DataFrame’leri birleştirme (pd.merge) işlemleri, iş sorularını cevaplamak için kritik olsa da, performans sorunları yaratır. Örneğin, “Hangi şirketlerin en uzun iş özetleri var?” gibi soruları cevaplamak zorlaşır.
GPU hızlandırması bu işlemlerde büyük bir hız artışı sağlar. Yan yana yapılan karşılaştırmayı izleyin:
Kodu detaylı incelemek için Colab veya GitHub bağlantılarına göz atın.
7.3 M Veri Noktası ile Etkileşimli PaneL Oluşturma
Veri analistlerinin temel hedeflerinden biri, paydaşların verileri keşfetmesine olanak tanıyan etkileşimli paneller oluşturmaktır. Bir panelin en önemli yönü, kullanıcı girdisine dayalı olarak verileri hızlı bir şekilde filtreleme yeteneğidir.
CPU’da pandas ile milyonlarca satırı gerçek zamanlı filtrelemek genellikle imkansızdır. Bir tarih kaydırıcısını veya açılır menüden bir değeri seçmek, gecikmeli ve kullanılmaz bir deneyime neden olabilir. Bu çalışma, between() ve isin() gibi pandas işlemlerinin kullanıcı tıklamalarıyla tetiklendiği 7.3 milyon hücresel kule konumu üzerine inşa edilmiş bir panel panelini göstermektedir.
GPU hızlandırması ile bu filtreleme işlemleri anlık hale gelir. Sonuç, milyonlarca coğrafi veri noktasını sorgularken akıcı bir panel deneyimidir.
Panele göz atmak için aşağıdaki videoyu izleyin:
Kodun tamamını incelemek için Colab veya GitHub üzerinden erişebilirsiniz.
Veri Çerçeveniz GPU Belleğinden Daha Büyükse Ne Olacak?
Sıkça karşılaştığımız bir soru, “Bu harika, ama veri setim GPU bellek kapasitemden fazla ise ne olacak?” şeklindedir.
Tarihsel olarak bu, büyük bir kısıtlama olmuştur. Ancak, **Unified Virtual Memory (UVM)** sayesinde, GPU’nuzun VRAM’inden (GPU’nun ayrılmış bellek alanı) daha büyük veri setleri üzerinde işlem yapabilirsiniz. UVM, verileri sisteminizin RAM’i ile GPU’nun belleği arasında akıllıca sayfalar, böylece büyük pandas DataFrame’leri üzerinde endişelenmeden çalışmanıza olanak tanır.
Daha fazla bilgi için bu blogu kontrol edebilir veya aşağıdaki videoyu izleyebilirsiniz.
Kendiniz Deneyin: Aynı Kod, Daha Fazla Hız
Görüldüğü üzere, pandas’taki performans darboğazları karmaşık çözümler gerektirmiyor. En yaygın performans sorunlarının çoğu, sahip olduğunuz GPU’yu etkinleştirerek çözülebilir.
En güzel yanı? **NVIDIA cuDF** ile mevcut pandas bilginiz yeterli olacaktır. GPU hızlandırmasını nasıl etkinleştireceğinize dair hızlı bir rehber:
Başlamak için hazır mısınız? Bu örnekleri ve daha fazlasını GitHub deposu üzerinden inceleyebilirsiniz.
Polars Kullanıcısı Mısınız?
Polars da **NVIDIA cuDF** tarafından desteklenen yerleşik bir GPU motoruna sahiptir. Daha fazla bilgi için Polars GPU Motoru bloguna göz atın.