
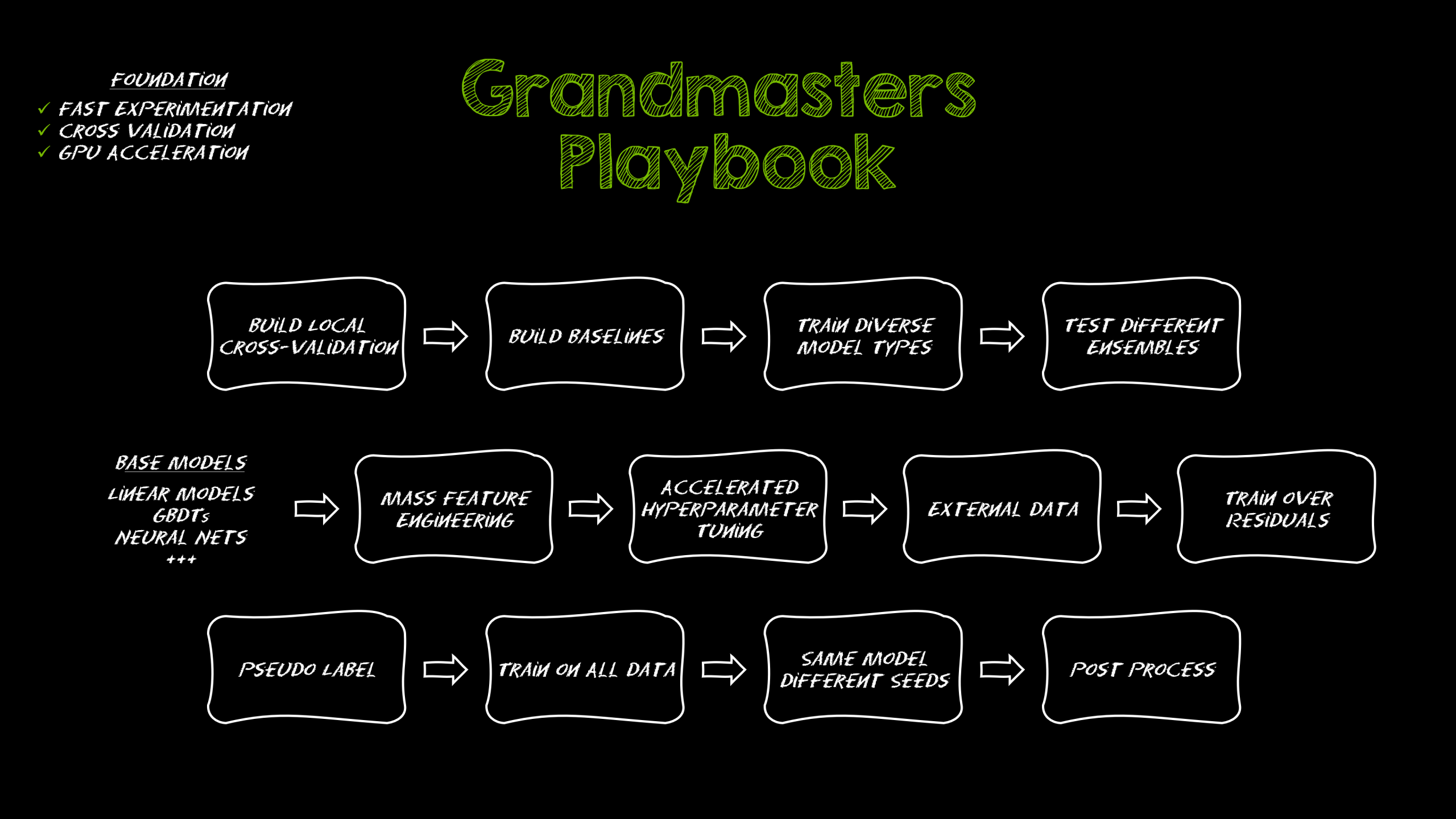
Yüzlerce Kaggle yarışmasında elde ettiğimiz deneyimlerle, her seferinde altıncı hissimize dayalı olarak puan tablosunun üst sıralarına yerleşen bir rehber oluşturduk. Milyonlarca satır, eksik değerler veya eğitim verileriyle uyuşmayan test setleriyle çalışıyor olsak da, bu sistem gerçek dünya tabularındaki sorunları hızlı bir şekilde çözmek için tekrarlanabilir bir yöntem sunuyor.
Aşağıda, sürekli olarak test ettiğimiz ve GPU hızlandırmasından faydalanarak uyguladığımız, yarışmalarda öne çıkmamızı sağlayan yedi teknik bulabilirsiniz. İster liderlik sırasını tırmanıyor olun, ister modellerinizi üretime alıyor olun, bu stratejiler size avantaj kazandırabilir.
Her bir teknik için geçmiş yarışmalardan örnek yazılara veya notlara bağlantılar ekledik.
Not: Kaggle ve Google Colab notları, aşağıda göreceğiniz hızlandırılmış sürümleri önceden yüklenmiş ücretsiz GPU’larla birlikte gelir.
Temel Prensipler: Bir Başarı Akışının Temelleri
Tekniklere dalmadan önce, bu rehberde her şeyi yönlendiren iki prensibi paylaşmak faydalı olacaktır: hızlı deney ve dikkatli doğrulama. Bunlar, her tabular modelleme problemine yaklaşımımızın temel taşlarıdır.
Hızlı Deney
Herhangi bir yarışma veya gerçek dünya projesinde en büyük etkimiz, gerçekleştirdiğimiz yüksek kaliteli deneylerin sayısıdır. Ne kadar çok deney yaparsak, o kadar çok desen keşfederiz ve bir modelin başarısız olduğunu, kayma yaşadığını veya aşırı öğrenme yaptığını erken fark ederek düzeltme yapabiliriz.
Pratikte bu, yalnızca model eğitim adımını hızlandırmakla kalmayıp, tüm boru hattımızı hız için optimize etmek anlamına gelir.
İşte nasıl çalıştığını sağlıyoruz:
- GPU sürümleri kullanan pandas veya Polars gibi veri çerçevesi işlemlerini hızlandırarak ölçeklenebilir biçimde özellikleri dönüştürüyoruz.
- NVIDIA cuML veya XGBoost, LightGBM ve CatBoost’un GPU sürümleri ile modelleri eğitiyoruz.
GPU hızlandırması yalnızca derin öğrenme içindir demek yanıltıcıdır; bu genellikle, gelişmiş tabular teknikleri ölçekli bir şekilde uygulamanın tek yoludur.
Yerel Doğrulama
Doğrulama puanınıza güvenemiyorsanız, gözlerinizi kapalı tutuyorsunuz demektir. Bu nedenle, çapraz doğrulama (CV) bizim iş akışımızın temel taşlarından birisidir.
Bizim yaklaşımımız:
- Modelin çoğu veride eğitildiği ve tutulmuş kısımda test edildiği k-katlı çapraz doğrulama kullanın.
- Her katmanı döndürerek, verinin her kısmının bir kez test edilmesini sağlayın.
Bu, tek bir eğitim/doğrulama ayırma işlemine göre çok daha güvenilir bir performans ölçümü sağlar.
İpucu: CV stratejinizi test verilerinin nasıl yapılandırıldığına göre eşleştirin.
Örneğin:
- Zamanla bağımlı veriler için TimeSeriesSplit kullanın.
- Gruplu veri (kullanıcılar veya hastalar gibi) için GroupKFold kullanın.
Bu temeller sağlam bir şekilde yerleştirilmiş olduğunda—hızla hareket edip dikkatlice doğrulama yaparak—şimdi tekniklerin kendisine dalabiliriz. Her biri bu ilkeler üzerine inşa edilmiştir ve ham veriyi dünya standartlarında modellere nasıl dönüştürdüğümüzü gösterir.
1. Daha Akıllı EDA ile Başlayın, Sadece Temel Bilgilerle Değil
Çoğu uygulayıcı, eksik değerler, aykırı değerler, ilişkiler ve özellik aralıkları gibi temel unsurları bilir. Bu adımlar önemlidir, ancak sadece başlangıç içindir. Gerçek dünyada dayanıklı modeller oluşturmak için verileri daha derinden keşfetmeli ve gözden kaçan bazı hızlı kontroller yapmalısınız:
Eğitim ve test dağılımı kontrolleri: Değerlendirme verilerinin eğitim verilerinden farklı olduğunu belirleyin, çünkü dağılım kayması, modellerin iyi doğrulandığı ancak üretimde başarısız olduğu anlamına gelebilir.
Hedef değişkenin zamansal kalıplarını analiz edin: Eğilimler veya mevsimsellik kontrolü yapın, çünkü zamansal kalıpları göz ardı etmek, eğitimde doğru görünen ancak üretimde kırılabilecek modellerin oluşturulmasına yol açabilir.
Neden önemli? Bu kontrolleri atlamak, başka bir sağlam iş akışını altüst edebilir.
Uygulamada: Amazon KDD Cup ‘23’teki zaferde, ekip hem bir eğitim-test dağılım kayması hem de hedefin zamansal kalıplarını keşfetti—bu içgörüler nihai yaklaşımı şekillendirdi.
GPU’larla pratik hale getirildi: Gerçek dünya verisetleri genellikle milyonlarca satır içerir, bu da pandas ile yavaşlayabilir. NVIDIA cuDF ile GPU hızlandırması ekleyerek, dağılım karşılaştırmaları ve korelasyonları ölçekli bir şekilde saniyeler içinde çalıştırabilirsiniz.
2. Hızla Farklı Temel Modeller Oluşturun
Çoğu kişi birkaç basit temel model oluşturur—belki bir ortalama tahmin, bir lojistik regresyon veya hızlı bir XGBoost ve sonra devam eder. Sorun şu ki, tek bir temel model veri manzarası hakkında çok fazla bilgi vermez.
Bizim yaklaşımımız farklı: Farklı model türlerinden oluşan çeşitli bir temel model seti hazırlıyoruz. Lineer modellerin, GBDT’lerin ve belki de küçük sinir ağlarının yan yana nasıl performans gösterdiğini görmek, deneylerimizi rehberlemek için çok daha fazla kontekst sunar.
Diverse basit modeller hem bazı metriklerde sonuçları artırarak, hem de veriyi daha iyi anlamamıza yardımcı olur.
Uygulamada:Yağmur Verileriyle İkili Tahmin yarışmasında hava durumu verilerinden yağmur miktarını tahmin etmemiz istendi. Temel modellerimiz, herhangi bir özellik mühendisliği yapmadan, gradient-boosted ağaçlar, sinir ağları ve Destek Vektör Regresyonu (SVR) modelleri kombinasyonu ile ikinci sırayı almamızı sağladı.
GPU ile pratik hale getirildi: Farklı modelleri eğitmek CPU üzerinde oldukça yavaş olabilir. GPU hızlandırması ile, onları denemek pratik hale gelir—cuDF hızlı istatistikler için, cuML lineer/lojistik regresyon için, ve GPU-hızlandırmalı XGBoost, LightGBM, CatBoost ve sinir ağları ile birkaç dakikada daha fazla içgörü alabilirsiniz.
3. Daha Fazla Özellik Üretin, Daha Fazla Kalıp Keşfedin
Özellik mühendisliği, tabular verilerde doğruluğu artırmanın en etkili yollarından biridir. Zorluk, binlerce özelliği pandas ile oluşturup doğrulamanın pratikte çok yavaş olmasıdır.
Neden önemli? Birkaç manuel dönüşümün ötesine geçmek, yüzlerce veya binlerce mühendislik özellikleri oluşturmak genellikle gizli sinyaller ortaya çıkarır; bu sinyaller modellerle tek başına yakalanamaz.
Örneğin: Kategorik sütunları birleştirme
Bir Kaggle yarışmasında, verisetinde sekiz kategorik sütun vardı. Bunların çiftlerini bir araya getirerek, orijinal verilerin göstermediği etkileşimleri yakalayacak 28 yeni kategorik özellik oluşturduk.
Uygulamada: Ölçeklenebilir özellik mühendisliği, Kaggle Sırt Çantası ve Sigorta yarışmalarında birincilik kazandırdı; burada binlerce yeni özellik farkı yarattı.
GPU ile pratik hale getirildi: cuDF ile pandas’daki grup, aggragasyon ve kodlama işlemleri çok daha hızlıdır, bu da binlerce yeni özelliği birkaç gün içinde üretip test etmenizi sağlar.
4. Birlikte Modelleri Kuvvetlendirerek Performansı Artırın
Farklı modellerin güçlü yönlerini bir araya getirmenin genellikle sağladığı performans artışını görüyoruz. İki teknik, özellikle faydalıdır: dağcılık (hill climbing) ve model istifleme (stacking).
4.1. Dağcılık (Hill Climbing)
Dağcılık, modelleri birleştirmek için basit ama etkili bir yöntemdir. En güçlü tekil model ile başlayın ve ardından farklı ağırlıklarla sistematik olarak diğer modelleri ekleyin; yalnızca doğrulamada iyileşme sağlayan kombinasyonları tutun. Tekrar edin ve ilerlemeye devam edin.
Neden önemli? İlerlemeyi sağlamak için, model birleştirmeleri arasındaki dengeyi bulmak zor olabilir. Dağcılık bu arayışı otomatikleştirir ve çoğu zaman tekil model çözümlerinin üzerinde doğruluk sağlar.
Uygulamada:Kalori Tüketimini Tahmin Etme yarışmasında, XGBoost, CatBoost, sinir ağları ve lineer modellerin bir dağcılık birleşimini kullanarak birinci oldum.
GPU ile pratik hale getirildi: Dağcılık kendisi yeni değildir—yalnızca cazip üst seviye yarışmalarda sıkça kullanılır. Ancak büyük ölçekte uygulanması genellikle çok yavaşlayabilir. CuPy sayesinde GPU’larda metrik hesaplamalarını vektörleştirerek çok sayıda ağırlık kombinasyonunu paralel olarak değerlendirme imkanı buluyoruz.
4.2. Stacking (İstifleme)
İstifleme, tekil modellerin çıktıları üzerinde bir model eğiterek ensemble yöntemini bir aşama daha ileri götürür. Ağırlıklarla tahminleri ortalayarak (dağcılık gibi) değil, diğer modellerin çıktılarının nasıl en iyi birleştirileceğini öğrenen ikinci seviyeden bir model oluşturarak ilerleme sağlanır.
Neden önemli? İstifleme, veri setinin karmaşık kalıplar barındırdığı durumlarda özellikle etkilidir; farklı modeller bu kalıpları farklı şekillerde yakalarlar.
İpucu: İkili istifleme yolları:
- Artıklar: Aşamalar arasındaki hatalar üzerinde ikinci aşama model eğitimi yapın.
- OOF Özellikler: Birinci aşama tahminlerini ikinci seviyenin yeni giriş özellikleri olarak kullanın.
Uygulamada: İstifleme, Podcast Dinleme Süresi yarışmasında birincilik elde etmemizde etkili oldu; burada, üç seviyeli bir istifleme kullanılarak farklı modeller (lineer, GBDT, sinir ağları ve AutoML) kullanıldı.
GPU ile pratik hale getirildi: İstifleme zaten iyi bilinen bir ensemble tekniğidir; ancak derin istifleme hesaplaması giderek daha fazla maliyetli hale gelir. GPU hızlandırmaları, çok seviyeli istiflemeler üzerinde anlamlı bir hız sağlıyor, bu da günler içinde makul bir hız elde etmemizi sağlıyor.
6. Sahipsiz Verileri Eğitim Sinyaline Dönüştürme
Pseudo-labeling (sahipsiz etiketleme), etiketlenmemiş veriyi eğitim sinyaline dönüştürme yöntemidir. En iyi modelinizi kullanarak verileri işaretlersiniz (örneğin, etiketlenmemiş veri veya harici veri setleri), ardından bu “pseudo-etiketleri” eğitim için geri entegre edersiniz.
Neden önemli? Daha fazla veri = daha fazla sinyal. Pseudo-labeling, dayanıklılığı artırır, bilgilendirme sağlamada etkili bir yöntemdir ve etiketli verileri gürültüden arındırmak için de kullanılabilir. Yumuşak etiketler (0/1 yerine olasılıklar kullanarak) ek düzenleme sağlar ve gürültüyü azaltır.
Etkin pseudo-labeling için ipuçları:
- Model ne kadar güçlü olursa, pseudo-etiketler o kadar iyi olur.
- Pseudo-etiketleri etiketli verilerde kullanmak; gürültülü örnekleri kaldırmak için faydalıdır.
- Sapma kaybı veya bilgi sızıntısından kaçınmak için dikkatli olun.
Uygulamada:BirdCLEF 2024 yarışmasında, görevimiz kuş ses kaydından türleri sınıflandırmaktı; pseudo-etiketleme ile etiketlenmemiş klipler üzerinden doğru etiketlerle eğitim setimizi genişlettik. Bu, modelimizin yeni türlere ve kayıt koşullarına daha iyi genelleşmesini sağladı.
GPU ile pratik hale getirildi: Pseudo-labeling genellikle birçok kez yeniden eğitim gerektirir. Ancak GPU hızlandırması ile, bir gün içinde birden fazla pseudo-labeling döngüsü yürütebilirsiniz.
7. Modelinizi Geliştirmek İçin Ekstra Eğitim Uygulayın
Tüm modellerimizi ve birleştirmelerimizi optimize etmemize rağmen, nihai performansı artırmak için iki son dokunuş daha keşfettik:
- Farklı rastgele tohumlarla eğitim yapın. Başlangıç ve eğitim yollarını değiştirip tahminleri ortalamak genellikle performansı artırır.
- Veri setinin %100’üyle yeniden öğretim yapın. Optimal hiperparametreleri bulduktan sonra, nihai modelinizi tüm eğitim verisi üzerinde eğitmek ekstra doğruluk sağlar.
Neden önemli? Bu adımlar yeni mimariler gerektirmez; yalnızca zaten güvenilir olan modellere daha fazla çalışma sağlar. Birlikte, dayanıklılığı artırabilir ve veri setinizi tam anlamıyla değerlendirdiğinizden emin olabilirsiniz.
Uygulamada:Optimal Gübreleri Tahmin Etme yarışmasında, XGBoost modellerinin 100 farklı tohumla birleşimi kesinlikle performansı artırdı. Tüm veri setinde yeniden eğitmek, diğer bir sıralama artışı sağladı.


Sonuç: Usta Rehberi
Bu rehber, yıllarca süren yarışmalardan ve sayısız deneyden edindiğimiz bilgileri içermektedir. Her projede uyguladığımız hızlı deney ve dikkatli doğrulama gibi iki temel prensibe dayanmaktadır. GPU hızlandırması sayesinde, bu gelişmiş teknikler ölçekli hale gelir ve gerçek dünya tabular sorunları için son derece etkili hale gelir.
Bu fikirleri pratiğe dökmek istiyorsanız, işte hızlandırılmış yönetim araçlarıyla ilgili başlamanız için bazı kaynaklar:
- Pandas ile Hızlandırma: Giriş Notu (Pandas iş akışları için sıfır kod değişikliği gerektiren hızlandırma)
- Scikit-learn ile Hızlandırma: Giriş Notu (Yaygın ML modelleri için hızlandırmalar)
- GPU Hızlandırılmış XGBoost: Giriş Notu (Milyonlarca satırda hızlı eğitim için)
- NVIDIA cuDF incelemesi: Pandas ve Polars’ı hızlandırmanın yolu.
- NVIDIA cuML incelemesi: Scikit-learn stili makine öğrenimi ile GPU hızlandırma.