


Bir zaman oradaydınız. Mükemmel bir Python betiği yazdınız, bir örnek CSV üzerinde test ettiniz ve her şey mükemmel gitti. Ancak, bu betiği 10 milyon satırlık tam veri kümesine saldığınızda, dizüstü bilgisayarınızın fanı gürültü çıkarmaya başladı, konsol dondu ve sonuç beklemek için üç şişe kahve yapacak kadar zamanınız oldu.
Peki ya mevcut iş akışlarınızda sadece basit bir bayrak veya parametre ile büyük hız kazançları elde edebileceğinizi söylesek?
Meğerse, Python’un en popüler veri bilimi kütüphanelerinden bazıları—pandas, Polars, scikit-learn ve XGBoost—şimdi çok az kod değişikliği ile GPU üzerinde çok daha hızlı çalışabiliyor. NVIDIA’nın cuDF, cuML ve cuGraph gibi kütüphanelerini kullanarak mevcut kodunuzu koruyabilir ve daha büyük iş yüklerini rahatça yönetebilirsiniz.
Bu yazıda, popüler Python kütüphanelerinin hızlı bir şekilde GPU üzerinde çalışmasını sağlayan yedi değiştirici hakkında bilgi paylaşacağız—denemek için başlangıç kodu da dahil!
Birçok Veriyi Hızla İşleyin: Pandas ve Polars ile GPU Kullanımı
Herhangi bir veri bilimi veya makine öğrenimi projesinin temeli veri hazırlığıdır. Genelde iş akışının en çok zaman alan kısmıdır, ancak böyle olmak zorunda değil.
#1: %%load_ext cudf.pandas: Pandas’ı GPU Hızlandırması ile Kullanma
Pandas, Python veri biliminin temel taşıdır, ancak büyük veri setlerinde hızla yavaşlar. cudf.pandas ile kodunuzu aynı şekilde tutup GPU hızlandırması alabilirsiniz.
Nasıl çalışır: Betiğinizin veya not defterinizin en üstüne cudf.pandas uzantısını yükleyin. cuDF, pandas komutlarınızı mümkün olduğunca GPU üzerinde akıllıca çalıştırır ve iş akışınızı önemli ölçüde hızlandırır.
# Betiğinizin başına bunu ekleyin!
%load_ext cudf.pandas
# Mevcut pandas kodunuz artık GPU üzerinde çalışıyor
import pandas as pd
df = pd.read_csv("büyük_veri_kümesi.csv")
# ... diğer pandas işlemleriniz artık hızlanmış durumda
Bu stok analizi iş akışının cudf.pandas etkinleştirildiğinde ne kadar hızlı çalıştığını izleyin:
Hemen deneyin:
#2: .collect(engine="gpu"): Polars’ı Daha Hızlı Hale Getirin
Polars zaten hızıyla tanınıyor. Şimdi güçlü sorgu optimizasyonunu cuDF’nin işleme gücü ile birleştirerek daha büyük bir performansa ulaşabilirsiniz.
Nasıl çalışır: Polars, GPU’yu kullanacak şekilde ayarlanabilen yerleşik bir yürütme motoruna sahiptir. cuDF destekli motoru etkinleştirerek Polars’a GPU’yu kullanmasını söylersiniz.
# "GPU" özellik bayrağı ile polars'ı yükleyin
pip install polars[gpu]
import polars as pl
# GPU motorunu toplama anında çağırma
(transactions
.group_by("CUST_ID")
.agg(pl.col("AMOUNT").sum())
.sort(by="AMOUNT", descending=True)
.head()
.collect(engine="gpu"))
GPU hızlandırmasının etkin olduğu ve olmadığı durumda aynı Polars sorgusunun nasıl çalıştığını izle:
Hemen deneyin:
Model Eğitimi: scikit-learn ve XGBoost ile GPU Hızlandırması
Veriniz hazır olduğunda, modellerinizi eğitmeye başlama zamanı gelir—burası birçok Python iş akışının zorluklarla karşılaştığı yerdir. scikit-learn ve XGBoost gibi kütüphaneler güçlüdür fakat büyük veri kümelerinde yavaşlayabilirler. Neyse ki, her ikisi de GPU hızlandırmasını açmanın ve eğitim süresini önemli derecede azaltmanın basit yollarını sunar.
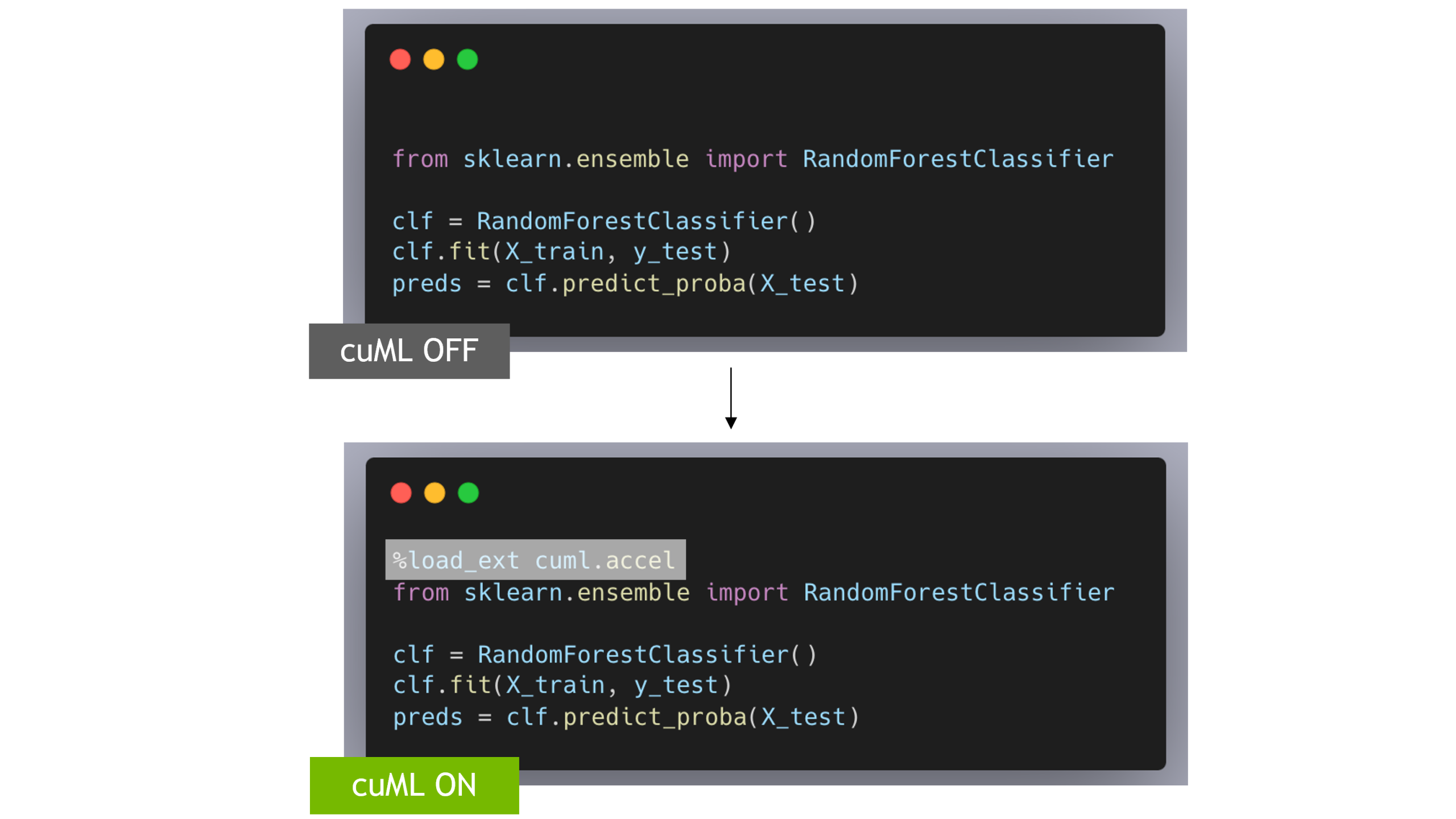
#3: %%load_ext cuml.accel: scikit-learn Modellerini Daha Hızlı Eğitin
Pek çok veri bilimcisi, sınıflandırma, regresyon ve kümeleme gibi günlük makine öğrenimi görevleri için scikit-learn’den faydalanır. Ancak veri büyüdükçe, hiperparametre ayarlamaları ve görselleştirme süreçleri eklendikçe eğitim süreleri artar. cuML ile, popüler scikit-learn modellerini GPU üzerinde hızlandırmak için herhangi bir kod değişikliğine gerek kalmadan zaman kazanabilirsiniz.
Nasıl çalışır: Sadece hızı artırmak için eklentiyi yükleyin ve scikit-learn kodunuzu olduğu gibi yazmaya devam edin. Arkada cuML, GPU üzerinde yürütmeyi halleder. Herhangi bir sözdizimi değişikliği yok. Yeni API yok.
%load_ext cuml.accel
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
X, y = make_classification(n_samples=500000, n_features=100, random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
rf = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)
rf.fit(X_train, y_train)
RandomForestClassifier eğitim süresinin dakikalar içinde saniyelere düştüğünü izleyin:
Hemen deneyin:
Not: cuML.accel, birçok yaygın scikit-learn modeli için kutudan çıktığı gibi çalışır; ancak kapsama alanı genişlemeye devam etmektedir. Bazı iş akışlarının kısmen CPU’ya düşmesi mümkün olabilir—detaylar için desteklenen tahmin edicilere bakın.
#4: device = "cuda": XGBoost’ta CUDA Hızlandırmasını Bir Parametre ile Aktifleştirin
XGBoost, GPU hızlandırmasıyla birlikte gelen dünyaca ünlü bir kütüphanedir. Sadece bunu etkinleştirmeniz gerekiyor.
Nasıl çalışır: Farklı bir kütüphaneye ihtiyacınız yok. Model başlatımı sırasında cihaz parametresini “cuda” olarak ayarlamak GPU’yu kullanmanızı sağlar.
# Cihazı "cuda" olarak ayarlayın
xgb_model = xgb.XGBRegressor(device="cuda")
xgb_model.fit(X,y)
GPU hızlandırmasının etkinleştirilmesi, model eğitimini hızlandırır ve özellik mühendisliği ile hiperparametre ayarlama sırasında daha hızlı tekrar denemeler yapmanızı sağlar—bu da modelleri daha kısa sürede test etme, geliştirme ve iyileştirme fırsatı sunar.
Hemen deneyin:
Keşifsel Makine Öğrenimi ve Kümeleme İş Akışlarını Hızlandırma
Modelinizi eğitmeden önce, veri setinizde yüksek boyutlu kalıpları keşfetmek veya kümeleri tanımlamak yaygındır. UMAP ve HDBSCAN gibi araçlar bu işi mükemmel bir şekilde yapar—ancak büyük veri setlerinde oldukça yavaş kalabilirler. cuML ile bu iş akışlarını çok daha hızlı çalıştırabilirsiniz.
#5: %%load_ext cuml.accel: UMAP Görselleştirmelerini Saniyelerde Oluşturun
UMAP, boyut indirgemenin güçlü bir tekniğidir, ancak büyük veri setlerinde fazlasıyla yavaş çalışabilir. cuML’in uygulaması, harika görselleştirmeleri çok daha kısa sürede oluşturmanıza olanak tanır.
Nasıl çalışır: scikit-learn ile olduğu gibi, yüklenecek olan uzantıyı değiştirin ve GPU ağır yükü üstlensin.
%%load_ext cuml.accel
import umap
umap_model = umap.UMAP(n_neighbors=15, n_components=2, random_state=42, min_dist=0.0)
# UMAP modelini verilerle uyumlu hale getirin
X_train_umap = umap_model.fit_transform(X_train_scaled)
cuML’in UMAP’ı hızlandırdığı gerçek bir veri setinde yan yana karşılaştırmayı izleyin.
umap-learn kodunun CPU ve GPU üzerinde çalışması. cuML’in hızlandırıcı modu sayesinde GPU versiyonu bir saniyenin altında çalışıyor—hiçbir kod değişikliği yapmadan.Hemen deneyin:
#6: %%load_ext cuml.accel: HDBSCAN Kümeleme Sürelerini Hızlandırma
Sıkı temelli kümeleme HDBSCAN, CPU üzerinde oldukça yavaş olabilir—özellikle yüksek boyutlu verilerle çalışırken. cuML’in hızlandırıcı modu sayesinde karmaşık yapıları saniyeler içinde açığa çıkarabilirsiniz.
Nasıl çalışır:cuml.accel uzantısını yükleyin ve mevcut HDBSCAN kodunuz otomatik olarak GPU üzerinde çalışır—yeniden yapılandırma gerekmez.
%%load_ext cuml.accel
import hdbscan
clusterer = hdbscan.HDBSCAN()
time clusterer.fit(X)
Büyük veri setleri ile HDBSCAN ile kümeleme, zaman alıcı olabilir—küçük örneklerde bile CPU işlemleri 30 ila 60 saniye sürebilir. cuML’in hızlandırıcı modu sayesinde HDBSCAN gibi kümeleme modellerini, bir saniye içinde mevcut Python kodunu kullanarak uyumlu hale getirebilirsiniz.
%load_ext cuml.accel – HDBSCAN kümeleme süresini 45 saniyeden 2 saniyenin altına düşürüyor. Hiçbir kod yeniden yazımına gerek kalmadan. Sadece uzantıyı yükleyin ve mevcut hdbscan kodunuzu kullanmaya devam edin.Hemen deneyin:
Graf Analitiği için NetworkX ile Ölçekleme
Grafikler, verilerdeki ilişkileri analiz etmek için son derece güçlüdür ve NetworkX, bunlarla çalışmak için en çok kullanılan kütüphanelerden biridir.
Graf yapılarını kolayca oluşturmanıza ve analiz etmenize olanak tanıyan yüzlerce işlev sunar. Ancak, saf Python uygulanması büyük veri setlerinde bir darboğaz haline gelebilir—CPU üzerinde gerçek dünya graf analitiğine ölçeklenmesini zorlaştırır.
#7: %env NX_CUGRAPH_AUTOCONFIG=True: NetworkX Grafikleri Ölçeklendirin
Bu ölçeklenebilirlik sınırlamalarını aşmak için, NetworkX ekosistemi artık cuGraph tarafından desteklenen bir GPU hızlandırmalı arka uç içeriyor; bu da nx-cugraph olarak bilinir. nx-cugraph ile mevcut NetworkX kodunuzu koruyarak GPU hızlandırmasını açabilirsiniz—hiçbir kod değişikliği gerektirmez.
Nasıl çalışır: nx-cugraph’ı yükleyin ve mevcut NetworkX kodunuzu çalıştırmadan önce çevresel değişkeni NX_CUGRAPH_AUTCONFIG=True olarak ayarlayın. NetworkX, nx-cugraph tarafından desteklenen algoritmaları otomatik olarak algılar ve bunları GPU’daki cuGraph’a yönlendirir—yeniden yazım veya dönüştürme gerektirmez.
# GPU destekli NetworkX arka ucunu yükleyin
pip install nx-cugraph-cu11 --extra-index-url https://pypi.nvidia.com
# NetworkX için GPU hızlandırmayı etkinleştirin
%env NX_CUGRAPH_AUTOCONFIG=True
# Mevcut NetworkX kodunuz aynı kalır
import pandas as pd
import networkx as nx
df = pd.read_csv("edgelist.csv", names=["src", "dst"])
G = nx.from_pandas_edgelist(df, source="src", target="dst")
centrality_scores = nx.betweenness_centrality(G, k=10)
CPU ve GPU üzerinde NetworkX’ün yan yana çalışmasını izleyin:
Hemen deneyin:
Sonuç: Aynı Kod, Daha Fazla Hız
CUDA uzmanı olmanıza gerek yok; GPU’ların büyük ölçekli paralel işleme gücünden faydalanmak oldukça kolay. Birçok veri bilimi ve makine öğrenimi iş akışı için araçlar zaten mevcut. cuDF, cuML ve cuGraph gibi kütüphaneleri kullanarak en sevdiğiniz araçları hızlandırabilir ve sonuçları daha hızlı elde edebilirsiniz.
Hazır mısınız? Bu blog gönderisinden tüm örnekler, defterler ve başlangıç kodları şu GitHub‘da bulunuyor.




