Kaggle yarışmalarını kazanmak için 2025 yılında neler gerekiyor? Nisan 2025 Playground yarışmasında, kullanıcıların bir podcast’i ne kadar süre dinleyeceğini tahmin etmek amaçlandı ve en iyi çözüm sadece doğru değil, aynı zamanda hızlıydı. Bu yazıda, Kaggle Grandmaster’ı Chris Deotte, GPU hızlandırmalı cuML kullanarak birincilik elde eden kesin istifleme stratejisini ele alacak. Bu şekilde, çok sayıda çeşitli modeli hızla keşfetmenin ve bunları üst düzey bir ansamblede birleştirip daha iyi bir performans elde etmenin güçlü bir yolunu öğreneceksiniz.
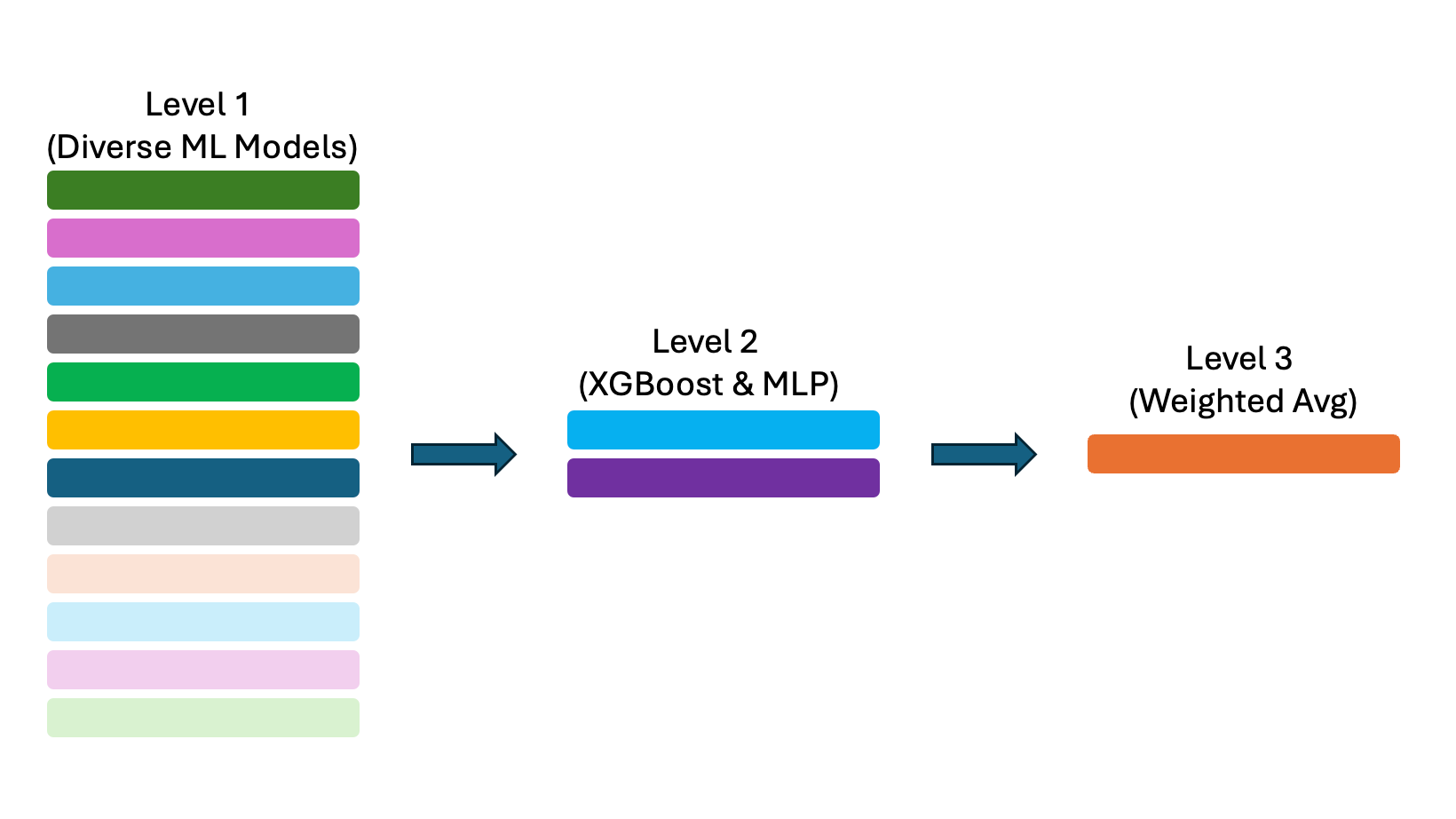
İstiflemenin Genel Görünümü
İstifleme, çok çeşitli modellerin tahminlerini birleştirerek yüksek performans elde edilmesini sağlayan ileri düzey bir tablo verisi modelleme tekniğidir. GPU’ların hesaplama hızını kullanarak, çok sayıda model verimli bir şekilde eğitilebilir. Bu modeller arasında gradyan artırımlı karar ağaçları (GBDT), derin öğrenme sinir ağları (NN) ve destek vektör regresyonu (SVR), k-en yakın komşu (KNN) gibi diğer makine öğrenimi (ML) modelleri bulunur. Bu bireysel modellere Seviye 1 modeller denir.
Ardından, Seviye 1 modellerinin çıktısını girdi olarak kullanan Seviye 2 modelleri eğitilir. Seviye 2 modelleri, farklı senaryolar için Seviye 1 modellerinin farklı kombinasyonlarını kullanarak hedefi tahmin etmeyi öğrenir. Son olarak, Seviye 2 modellerinin çıktısını ortalayan basit Seviye 3 modelleri eğitilir. Bu süreç sonunda üç düzeyli bir yığın elde edilir.
Şekil 1, 12 tane Seviye 1 modelini göstermektedir. Nihai çözüm, 500 deneysel model arasından seçilen 75 Seviye 1 modelini kullanmıştır. Güçlü bir yığın oluşturmanın sırrı, birçok Seviye 1 modelini keşfetmektir. Bu nedenle, GBDT, NN ve ML modellerini GPU ile olabildiğince hızlı bir şekilde eğitmek kritik öneme sahiptir. Bu işlem, GPU üzerinde ML modellerini hızlandıran cuML kullanılarak gerçekleştirilmektedir.

Hedefi Tahmin Etmek İçin Çeşitli Yaklaşımlar
Çeşitli modeller, bir problemi farklı şekillerde çözerek inşa edilir. Farklı model türleri, mimarileri ve hiperparametreleri kullanılabileceği gibi, farklı ön işleme yöntemleri ve özellik mühendisliği de uygulanabilir.
Nisan 2025 Kaggle Playground yarışmasında, Podcast Dinleme Süresinin hedefini tahmin etmenin en az dört farklı yolu vardı. Hedef Listening_Time_minutes, yaklaşık olarak 0.72 x Episode_Length_minutes doğrusal ilişkisine eşittir. Daha fazla detay için, Güçlü Özellik Etkileşimi Mevcuttur, Doğrudan ve Dolaylı – Hedef ile İlişki ve Özellikler ile Hedef Arasında Güçlü Korelasyon başlıklarına göz atabilirsiniz. Diğer dokuz özellik, bu doğrusal ilişkiyi etkiler.

Episode_Length_minutes ile hedef Listening_Time_minutes arasındaki güçlü doğrusal ilişkiyi gösteren dağılım grafiği.Şekil 2’de yer alan içgörülere dayanarak, hedefi tahmin etmenin en az aşağıdaki dört yolu vardır:
- Hedef olarak doğrudan tahmin etme
- Hedefin episode length minutes ile oranını tahmin etme
- Doğrusal ilişkiden residual tahmin etme
- Kayıp
episode_length_minutestahmin etme
Bu dört yaklaşımın her birinin iki durumu vardır:
- Row sayısının %88’inde episode length minutes bulunmaktadır.
- Row sayısının %12’sinde episode length minutes kayıptır.
Hedefi Tahmin Etme
Bir modeli inşa etmenin en yaygın yolu, verilen hedefi kullanmaktır. Verilen 10 özellik sütunu ile ek özellik sütunları üretebilir ve ardından bu özelliklerle modelinizi eğiterek hedefi tahmin edebilirsiniz:
model = Regressor().fit(train[FEATURES], train['Listening_Time_minutes'])
PREDICTION = model.predict(train[FEATURES])
Bu tek başına, Şubat 2025 Kaggle Playground yarışmasında birinciliği kazandırdı. Daha fazla detay için, Grandmaster Pro İpucu:Kaggle Yarışmasında Özellik Mühendisliği ile Birincilik Kazanmak başlıklı yazıya göz atabilirsiniz.
Oranı Tahmin Etme
Verilen hedefi tahmin etmenin bir alternatifi, hedef ile Episode_Length_minutes arasındaki oranı tahmin etmektir:
train['new_target'] = train.Listening_Time_minutes / train.Episode_Length_minutes
Bunu yaptıktan sonra, bu yeni hedefi tahmin eden modeller eğitebilirsiniz. Ardından, bu tahmin ile Episode_Length_minutes‘i veya bir eksik değeri çarparak gerçek hedefi tahmin edebilirsiniz.
Kalıntıyı Tahmin Etme
Verilen hedefi tahmin etmenin bir diğer yolu ise, hedef ve bir doğrusal regresyon modeli arasındaki kalıntıyı tahmin etmektir. Öncelikle bir doğrusal regresyon modeli eğitip tahmin ettikten sonra, hedefin mevcut değerinden bu tahmin edilen değeri çıkartarak yeni bir hedef oluşturabilirsiniz:
model = LinearRegressor().fit(train[FEATURES], train['Listening_Time_minutes'])
LINEAR_REGRESSION_PREDS = model.predict(train[FEATURES])
train['new_target'] = train.Listening_Time_minutes - LINEAR_REGRESSION_PREDS
Bu yeni hedef ile tahmin eden modeller eğitebilir ve ardından bu tahmini doğrusal regresyon modelinizin tahminine ekleyebilirsiniz.
Kaybolan Özellikleri Tahmin Etme
Episode_Length_minutes özelliği en önemli özelliktir, ancak %12 oranında eğitim satırlarında eksiktir. Bu özelliği tahmin etmek için ayrı bir model inşa edebilir ve ayrıca episode_length_minutes mevcut olan tüm eğitim ve test verilerini kullanma fırsatını değerlendirebilirsiniz:
combined = cudf.concat([train, test], axis=0)
model = Regressor().fit(combined[FEATURES], combined['Episode_Length_minutes'])
Episode_Length_minutes_IMPUTED = model.predict(train[FEATURES])
Sonrasında, bu tahmin edilen Episode_Length_minutes değerini kullanarak gerçek hedefi tahmin edebilirsiniz:
- Kayıp değerleri
Episode_Length_minutesile doldurarak bir model eğitme - Tüm
Episode_Length_minutessütununu değiştirmek ve model eğitmek - Tahmin edilen
Episode_Length_minutesile tahmin edilen oranı çarparak hedef tahmini yapma
Pseudolabel Tahmini
Önceki bölümlerde, test veri sütunlarını kullanarak eğitim verilerinde kaybolan değerlerin imputes edilmesine dair bir yöntem gösterilmiştir. Ancak bir diğer güçlü bir teknik de pseudolabelingdir. Pseudolabeling, üç aşamalı bir süreçten oluşur:
- Modelleri normal şekilde eğitin
- Test verileri için etiketleri tahmin edin
- Pseudolabel test verilerini eğitim verileri ile birleştirip başka bir model eğitin
Aşağıdaki kod, basit bir örnektir. Eğer K-Fold ya da Nested K-Fold’ı kullanırsanız, genellemenin daha iyi olmasını sağlayabilir ve sızıntıyı önleyebilirsiniz:
model1 = Regressor().fit(train[FEATURES], train['Listening_Time_minutes'])
test['Listening_Time_minutes'] = model1.predict(test[FEATURES])
combine = cudf.concat([train, test], axis=0)
model2 = Regressor().fit(combine[FEATURES], combine['Listening_Time_minutes'])
Yığının Oluşturulması
GBDT, NN, ML kullanarak birçok çeşitli modeli eğittikten sonra, bir sonraki adım yığın oluşturmaktır. Seviye 1 modellerinin alan dışı (OOF) tahminleri, Seviye 2 modelleri için özellik olarak eklenir. Ayrıca orijinal veri setinden ek özellikler ve OOF tahminlerinden elde edilen mühendislik özellikleri de dahil edilebilir. Örneğin, modelin güveni ya da ortalama tahmin gibi:
df['confidence'] = df[OOF].std(axis=1)
df['concensus'] = df[OOF].mean(axis=1)
Çeşitlilik sağlamak amacıyla, birden fazla Seviye 2 modeli eğitmek en iyisidir. İyi bir seçim, bir GBDT ve bir NN Seviye 2 modelidir. Seviye 3 için, Seviye 2 tahminlerinin ağırlıklandırılmış ortalamasını almak yeterlidir. Sonuç, nihai tahmin olacaktır.
İstiflemenin bu ileri düzey tekniği, CV doğrulama metriği RMSE = 11.54 ve özel lider tahtası RMSE = 11.44 gibi sonuçlar elde etmiştir. Bu sonuç, Nisan 2025 Kaggle Playground yarışmasında podcast dinleme sürelerini tahmin ederek birincilik kazandırmıştır.
Özet
cuML, artık GPU hızında tüm istatistiksel ML modellerini oluşturmanıza olanak tanıyor. GPU ile GBDT, NN ve artık GPU ile cuML kullanarak modeller oluşturabilirsiniz. Çeşitli modelleri hızlı bir şekilde oluşturarak, gelişmiş tablo verisi çözümleri gibi yığınlar kurabilirsiniz.
Hızlı deneyimleme, en doğru çözümleri keşfetmenize olanak tanır. Bu, Nisan 2025 Kaggle Playground yarışmasında podcast dinleme sürelerini tahmin ederken cuML yığınının birinci olmasıyla kanıtlanmıştır. Yarışmaya katılım hakkında daha fazla bilgi almak için Birinciliğin Kazanılması – RAPIDS cuML Yığını – 3 Düzey başlığına bakabilirsiniz.
Daha fazla ipucu ve cuML kullanımı hakkında bilgi almak için NVIDIA GTC 2025 atölyelerine göz atın, Özellik Mühendisliği veya Python’da Veri Bilimine Hızlandırılmış Hesaplamayı Getirin gibi konularda eğitim alabilir veya NVIDIA DLI Öğrenme Yolu kurslarına katılabilirsiniz.