
Robotların 3D Algılama Yeteneği
Robotların 3D ortamlarını algılayıp yorumlaması, güvenli ve etkili bir şekilde hareket edebilmesi için hayati öneme sahiptir. Bu, özellikle otonom navigasyon, nesne manipülasyonu ve düzensiz veya tanıdık olmayan alanlarda teleoperasyon gibi görevlerde kritik bir faktördür. Robotik algılama alanındaki ilerlemeler, giderek daha fazla 3D sahne anlama, genellenebilir nesne takibi ve sürekli mekansal hafıza entegrasyonuna odaklanmaktadır; bu sayede güçlü algılama modülleri, birleşik ve gerçek zamanlı iş akışlarında kullanılabilir hale gelmektedir.
NVIDIA Araştırma ve Geliştirme Raporu
Bu NVIDIA Robotics Araştırma ve Geliştirme Raporu (R2D2) eklentisi, NVIDIA Araştırma tarafından geliştirilen ve robotik için birleşik bir 3D algılama yığını destekleyen çeşitli algılama modellerini ve sistemlerini keşfetmektedir. Bu sistemler, farklı gerçek dünya ayarlarında güvenilir derinlik tahmini, kamera ve nesne poz takibi ile 3D yeniden yapılandırma yapılmasına olanak sağlar:
- FoundationStereo (CVPR 2025’te En İyi Makale Adayı): Farklı iç mekan, dış mekan, sentetik ve gerçek dünya sahnelerinde genel performansa sahip, stereoskopik derinlik tahmini için tasarlanmış bir temellendirme modelidir.
- PyCuVSLAM: NVIDIA’nın CUDA hızlandırmalı SLAM kütüphanesinin Python kullanıcıları için gerçek zamanlı kamera poz tahmini ve çevre haritalama uygulamasını sağlayan bir Python sarmalayıcısıdır.
- BundleSDF: RGB-D video üzerinden 6-DoF nesne poz takibi ve yoğun 3D yeniden yapılandırma için bir sinir ağı sistemidir.
- FoundationPose: Minimum ön bilgi ile yeni nesneler için genellenebilir 6D nesne poz tahmin edici ve takipçi bir sistemdir.
- nvblox Pytorch Sarmalayıcısı: PyTorch için derinlik kameralarından 3D yeniden yapılandırma yapabilen CUDA hızlandırmalı nvblox kütüphanesi için bir PyTorch sarmalayıcısıdır.
3D Mekansal Temsiller: Robot Algılamasının Temeli
Bu projelerin merkezinde, robotun kullanabileceği bir şekilde çevrenin ya da nesnelerin yapısını yakalama amacıyla geliştirilen 3D mekansal temsillere vurgu bulunmaktadır. FoundationStereo, stereoskopik görüntülerden derinlik tahmininin temel görevine odaklanmakta ve güçlü sıfırdan genel bir performans sağlamak için tasarlanmış bir temel model sunmaktadır.


FoundationStereo, 1 milyondan fazla sentetik stereo çiftlerle eğitilmiştir. İçi ve dışı dahil olmak üzere çeşitli ortamlarda doğru disparite tahmini yapabilmekte, böylece 3D yapı oluşturabilmektedir. Çıktıları, sahnenin 3D yapısını temsil eden yoğun derinlik haritaları veya nokta bulutlarından oluşmaktadır.
Çevre haritalama tarafında, nvblox ve cuVSLAM gibi kütüphaneler, zamanla mekansal temsilleri oluşturmaktadır. NVIDIA’nın nvblox kütüphanesi, voxel ızgaraları yeniden inşa eden ve navigasyon için Avrupa imzalı mesafe alanı (ESDF) ısı haritaları çıkaran bir GPU hızlandırmalı 3D yeniden yapılandırma kütüphanesidir. Bu sistem, mobil robotlar için görsel tabanlı 3D engel önleme sağlamakta olup, pahalı 3D lidar sensörlerine uygun ekonomik bir alternatif sunmaktadır.
Öte yandan, nvblox geometrik haritalama konusundaki performansı ile öne çıkarken, çevrenin anlamsal anlayışında eksiklik göstermektedir. nvblox_torch ile, 2D VLM temel modelinin anlamsal gömüsünü 3D’ye taşıyan yeni bir yetenek eklenmiştir.
Aynı şekilde, cuVSLAM, Isaac ROS ile robotlar için GPU hızlandırmalı görsel-ivme SLAM sunmaktadır. Daha önce yalnızca ROS kullanıcılarına sunulmuş olan cuVSLAM, PyCuVSLAM adlı yeni bir Python API’si sayesinde artık daha geniş bir kullanıcı kitlesine ulaşabilmektedir. Bu API, veri mühendisleri ve derin öğrenme araştırmacıları için entegrasyonu kolaylaştırmaktadır.
Derinlik ve haritalama modülleri, yüksek seviyeli algılama ve planlamanın temellerini oluşturacak şekilde, nokta bulutları, işaretli mesafe alanları veya özellik ızgaraları şeklinde geometrik iskeletler oluşturur. Güvenilir 3D temsiller olmadan, bir robot dünyasını doğru bir şekilde algılayamaz, hatırlayamaz veya akıl yürütemez.
Gerçek Zamanlı SLAM ve Kamera Poz Tahmini
Bu projeleri birleştiren ana unsur, SLAM (Eşzamanlı Konumlandırma ve Haritalama) aracılığıyla gerçek zamanlı sahne anlayışıdır. CuVSLAM, bir robotun yerleşik GPU’su üzerinde çalışan en verimli ve CUDA hızlandırmalı SLAM sistemidir.


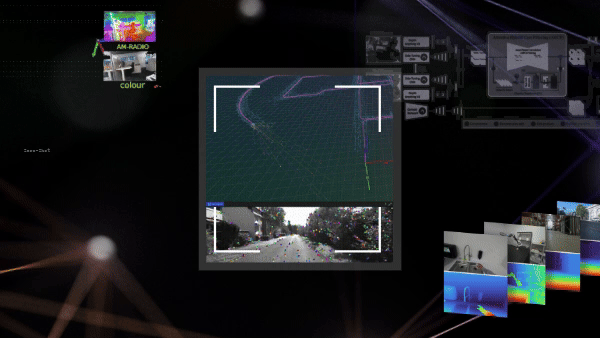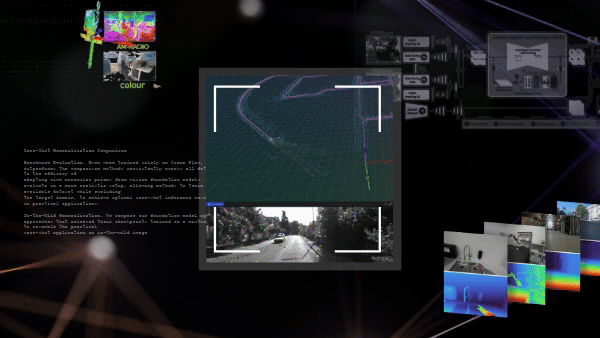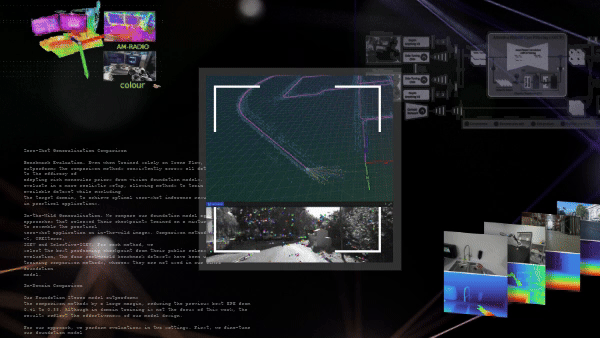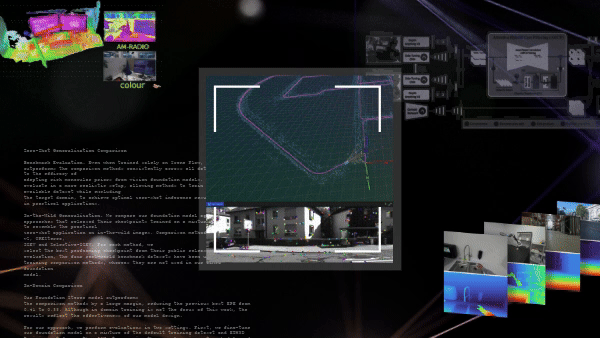
Güçlü ve etkin görsel SLAM sistemleri kullanmak, Python’un basitliği ve çok yönlülüğünü tercih eden geliştiriciler için zorlayıcı bir görev olmaya devam etmektedir. PyCuVSLAM ile, geliştiriciler cuVSLAM’ı uygulamaları için kolaylıkla prototipleme ve kullanma imkanı bulmaktadır. API, bir kamera kullanıcısının, birinci şahıs video görüntülerinden poz ve yol tahmin edebilmesini sağlar. Ayrıca cuVSLAM’ı MobilityGen gibi eğitim boru hatlarına entegre etmek, gerçek dünya SLAM sistem hatalarından öğrenerek daha dayanıklı modeller oluşturabilir. Örnek yetenekler, Şekil 2’de gösterilmektedir.
Gerçek Zamanlı 3D Haritalama


Nvblox_torch, geliştiricilerin manipülasyon ve navigasyon uygulamaları için 3D haritalama sistemleri prototipini kolaylıkla oluşturmasına olanak tanıyan kullanıcı dostu bir Python arayüzüdür.
Bir robotun daha uzun vadeli görevleri yerine getirebilmesi için mekansal hafıza oluşturması kritik bir yetenektir. Robotlar, çevrelerinde bir sahnenin geometrik ve anlamsal içeriği hakkında akıl yürütebilme yeteneğine sahip olmalıdır; genellikle sahne, tek bir kamera görüntüsü ile yakalanamayacak kadar geniştir. Bir 3D harita, birden fazla görünüm aracılığıyla geometrik ve anlamsal bilgileri bir araya getirerek sahnenin birleşik bir temsilini oluşturur. 3D haritaların bu özellikleri, robot öğrenimi bağlamında mekansal hafızayı ve mekansal akıl yürütmeyi destekleyebilir.
Nvblox_torch, RGB-D kameralarla robot haritalama yapabilen CUDA hızlandırmalı bir PyTorch araç setidir. Sistem, çevredeki gözlemleri 3D temsil noktasına dönüştürerek NVIDIA GPU’sunda işlemektedir. Bu 3D temsil daha sonra engel uzaklığı, yüzey ağları ve doluluk olasılığı gibi ölçümleri sorgulamak için kullanılabilir (bkz. Şekil 3). Nvblox_torch, PyTorch tensörlerinden minimum gecikme ile veri girişi/çıkışı sağlayarak olağanüstü hızlı bir performans sunmaktadır.
Üstelik, nvblox_torch yeni bir yetenek eklemektedir: derin özellik füzyonu. Bu özellik, kullanıcıların görsel temel model özelliklerini 3D yeniden yapılandırma yaparken birleştirmesine olanak tanımaktadır. Ortaya çıkan yeniden yapılandırma, hem geometrik hem de anlamsal sahne içeriğini temsil etmektedir. 3D alanında temel model özellikleri, anlamsal tabanlı navigasyon ve dil ile yönlendirilmiş manipülasyon için popüler bir temsil olarak ortaya çıkmaktadır. Bu temsil artık nvblox_torch kütüphanesinde mevcuttur.
6-DoF Nesne Poz Takibi ve Yenilikçi Nesne 3D Yeniden Yapılandırma
Nesne merkezli algılamanın bir diğer önemli yönü, sahnedeki nesneleri tanıma, konumlarını belirleme ve hareketlerini izlemektir. FoundationPose ve BundleSDF projeleri, daha önce hiç görülmemiş nesneler için bile 6-DoF poz tahmin ve takibi konusundaki zorluğu ele almaktadır.
FoundationPose, model tabanlı ve modelden bağımsız senaryoları kapsayan 6D nesne poz tahmin ve takibi için birleşik bir model sunmaktadır. Bu sistem, aynı zamanda CAD modeli mevcut olan bilinen nesnelerin (varsa) yanı sıra sadece birkaç referans görüntüsü ile tamamen yeni nesneleri (yeniden eğitim gerektirmeden) işleyebilmektedir. FoundationPose, nesnenin görünümünü sentezlemek için sinirsel bir gizli temsil kullanarak, tam 3D modele sahip olmanın ve sadece seyrek gözlemlerin nasıl bir araya getirileceği arasında köprü kurmaktadır.
Büyük ölçekli sentetik veri ile eğitilmiş olup (LLM tabanlı veri üretim hattı gibi tekniklerin desteğiyle), sağlam bir şekilde genellenmektedir; aslında yeni bir nesne için test aşamasında anında uygulanabilmektedir. Bu temel model yaklaşımı, poz benchmark’larında son nokta doğruluğu sağlayarak özel yöntemleri geride bırakmakta ve yeni nesneler üzerinde sıfırdan yetenek sunmaktadır.


BundleSDF, RGB-D video üzerinden eşzamanlı 6-DoF poz takibi ve sinirsel 3D yeniden yapılandırma için çevrim içi, optimizasyon odaklı bir yaklaşım sunmaktadır. İlk çerçevede yalnızca segmentasyon gerektirmekte; bundan sonra CAD modeli veya kategori bilgisine ihtiyaç duymamaktadır.
BundleSDF’nin temelinde, nesnenin geometrisini ve görünümünü gözlemlendiği gibi yakalayan eşzamanlı öğrenilen bir Sinirsel Nesne Alanı bulunmaktadır. Nesne hareket ettikçe, BundleSDF, geçmiş çerçeveleri kullanarak bir poz grafi optimize etmekte ve poz yolunu ile şekil tahminini zamanla iyileştirmektedir. Poz tahminini şekil öğrenimi ile entegre etmek, büyük poz değişimleri, gizleme, düşük dokulu yüzeyler ve parlak yansımalar gibi zorlukların üstesinden gelinmesine yardımcı olmaktadır. Bir etkileşim sonunda robot, hareket halindeyken elde ettiği tutarlı bir 3D model ve izlenmiş poz dizisine sahip olmaktadır.
Çerçevenin genel yapısı Şekil 5’te gösterilmektedir. İlk olarak, ardışık görüntüler arasında özellikler eşleştirilerek kaba bir poz tahmini elde edilmektedir. Bazı pozlanmış çerçeveler daha sonraki iyileştirme için bir bellek havuzunda saklanmaktadır. Poz grafi havuzdan dinamik bir alt kümeden oluşturulmakta ve çevrimiçi optimizasyon, grafikteki tüm pozları ve mevcut pozları iyileştirmektedir. Güncellenmiş pozlar tekrar havuza kaydedilmektedir. Son olarak, havuzdaki tüm pozlanmış çerçeveler, nesne geometrisi ve görsel dokuyu modelleyen bir Sinirsel Nesne Alanı öğrenmektedir.


Hem FoundationPose hem de BundleSDF, robotiklerde nesne seviyesinde 3D anlayışın önemini vurgulamaktadır. Bir robotun rastgele nesneleri alabilmesi veya manipüle edebilmesi, nesnenin 3D konumunu ve yönünü (pozunu) doğru bir şekilde algılayabilmesine bağlıdır. Bu projeler, temel modeller sayesinde yeni nesneleri tanımlamayı sağlarken, çevrimiçi sinirsel SLAM, nesne hareket halindeyken bir özelleştirilmiş modeli oluşturma imkanı sunmaktadır. Uygulamada, bu yeteneklerin işbirliği yapması muhtemeldir; örneğin, bir temel model, çevrimiçi yeniden yapılandırma ile iyileştirilen bir ilk tahmin sunabilir.
Temel Modellerin Genel Performansı
Daha fazla robotik algılama sistemi, minimum ince ayar ile birden çok görevi genelleştiren büyük sinirsel ağlar olan temel modellere yönelmiştir. Bu durum, FoundationStereo ve FoundationPose gibi projelerde de görülmektedir; bu projeler, sırasıyla stereo derinlik tahmini ve 6D nesne poz takibi için güçlü temel sunmaktadır.
FoundationStereo, stereo model çerçevesine, DepthAnythingV2’den, ikincil ayarlanmış bir monoküler derinlik öncüsü ekleyerek sağlamlığı ve alan genelgelemesini artırmaktadır. Çeşitli ortamlarda 1 milyondan fazla sentetik stereo çiftle eğitilmekte ve Middlebury, KITTI ve ETH3D veri setleri üzerinde sıfırdan performans göstererek, endüstrideki en iyi konumda yer almaktadır. Model, uzun menzilli disparite tahminini geliştiren hem maliyet hacmi kodlayıcısını hem de çözücüsünü iyileştirmektedir.
Şekil 6’da, Kenar Ayarı Adaptörü (STA) donmuş DepthAnythingV2’den gelen zengin monoküler öncüller ile çok seviyeli CNN’den elde edilen detaylı yüksek frekanslı özelliklerin nasıl bir arada kullanıldığı gösterilmektedir. Dikkatli Hibrit Maliyet Filtreleme (AHCF), düzlemsel hibrid maliyet hacmindeki özellikleri etkili bir şekilde bir araya getirerek, boyutsal ve disparite boyutları arasında verimli bir filtreleme sağlar. Filtrelenmiş bu maliyet hacminden bir ilk disparite tahmini yapılmakta ve GRU blokları kullanılarak iyileştirilmektedir.


FoundationPose, yeni nesnelerin tek çerçevede 6D poz tahmini ve çok çerçevede poz takibi için birleşik bir model sunmaktadır. Hem model tabanlı hem de görüntü tabanlı tahmini destekler ve nesne geometrisinin sinirsel bir gizli temsilini öğrenmektedir. Sadece birkaç RGB referans görüntüsü kullanarak veya mevcut bir CAD modeli ile, daha önce görülmemiş nesnelere genellenebilir. Büyük bir sentetik veri kümesi üzerinde eğitilen bu model, organik görev istemleri ve sahne varyantları içermektedir.
FoundationPose, kontrastif eğitim ve bir dönüştürücü tabanlı kodlayıcı kullanarak, CosyPose ve StablePose gibi görev spesifik tabanlılarının önemli şekilde gerisinde kalmadan herhangi bir poz benchmark’ında yüksek performans sunmaktadır. Şekil 7, FoundationPose’un nasıl çalıştığını göstermektedir. Büyük ölçekli eğitimi kolaylaştırmak amacıyla, 3D model veritabanı, LLM’ler ve difüzyon modelleri gibi yeni tekniklerin kullanıldığı sentetik veri üretim hattı oluşturulmuştur. Model tabanlı ve modelden bağımsız sistemleri bağlamak için, yeni görünüm RGB-D render yapımında nesne merkezli bir sinir alanı kullanılmıştır.


Tüm bu modeller, robotiklerde birleşik ve yeniden kullanılabilir algılamanın temellerinin atılmasına olanak tanımaktadır. Derinlik ve nesne geometrisi hakkında genel amaçlı öncüller, sistemlere gömüldüğünde, sıfırdan senaryolarında güvenilir performans sağlar; bu da robotların, eğitim sırasında görülmemiş ortamlarda veya nesnelerle çalışabilmesine imkan tanır. Robotiklerin daha uyumlu ve açık dünya uygulamalarına doğru ilerlemesiyle, temel modeller, ortak bir algılama çerçevesinde geniş bir görev yelpazesini desteklemek için gerekli esneklik ve ölçeklenebilirliği sunmaktadır.
Birleşik 3D Algılama Yığınına Doğru
Tüm bu projeler, derinlik tahmini, SLAM, nesne takibi ve yeniden yapılandırmanın sıkı bir şekilde entegre bileşenler olarak çalıştığı bir birleşik 3D algılama yığınına işaret etmektedir. FoundationStereo güvenilir derinlik sağlamakta; cuVSLAM kamera pozunu gerçek zamanlı yer belirleme ve haritalama için takip etmekte; BundleSDF ve FoundationPose, yeni nesnelerin bile 6-DoF takibini ve şekil tahminini gerçekleştirmektedir.
Temel model ve sinirsel 3D temsillerinden faydalanarak, bu sistemler, karmaşık ortamlarda navigasyon, manipülasyon ve etkileşim destekleyen genellenebilir, gerçek zamanlı algılama sağlamaktadır. Robotiklerin geleceği, algılama modüllerinin, mekansal ve anlamsal farkındalıkla robotların algılama, hafızasını oluşturma ve hareket etmesine olanak sağlayacak bağlamları paylaştığı bu gibi entegre yığınlardadır.
Özet
Bu R2D2 bölümü, son zamanlarda stereo derinlik tahmini, SLAM, nesne poz takibi ve 3D yeniden yapılandırmadaki ilerlemelerin robotlar için birleşik bir 3D algılama yığınına nasıl ustalıkla entegre edildiğini keşfetti. Bu araçlar, robotların, tanımadıkları nesne ve sahnelerle karşılaştıklarında çevrelerini anlamalarını ve etkileşimde bulunmalarını sağlamaktadır.
Aşağıdaki kaynakları inceleyerek daha fazla bilgi edinebilirsiniz:
- FoundationStereo (CVPR 2025 – En İyi Makale Adayı) – Web Sitesi, makale, kod ve veri seti.
- FoundationPose (CVPR 2024 Vurgusu) – Web Sitesi, makale, kod, NGC, Isaac ROS FoundationPose
- BundleSDF (CVPR 2023) – Web Sitesi, makale, kod
- PyCuVSLAM – Makal, kod
- nvblox_torch – Web Sitesi, makale, kod
Yakında:
- FoundationStereo ticari versiyonu.
Tüm NVIDIA araştırma makalelerine ve CVPR 2025’teki sunumlara göz atın ve araştırmanın uygulamada nasıl olduğunu izleyin.
Bu yazı, NVIDIA Araştırma tarafından ortaya konulan son yenilikleri geliştiricilere tanıtmak amacıyla hazırlanan NVIDIA Robotics Araştırma ve Geliştirme Raporu (R2D2) serisinde yer almaktadır.
Gelişmelerden haberdar olmak için bültene abone olun ve NVIDIA Robotics’i YouTube, Discord ve geliştirici forumlarıında takip edin. Robotik yolculuğunuza başlamak için ücretsiz NVIDIA Robotik Temelleri kurslarına kaydolun.
Teşekkürler
Bu yazıda bahsedilen araştırmalara katkıda bulunan Joseph Aribido, Stan Birchfield, Valts Blukis, Alex Evans, Dieter Fox, Orazio Gallo, Jan Kautz, Alexander Millane, Thomas Müller, Jonathan Tremblay, Matthew Trepte, Stephen Tyree, Bowen Wen ve Wei Yang’a teşekkür ederiz.