


Robot teknolojileri alanındaki en büyük zorluklardan biri, her yeni görev ve ortam için büyük veri setleri toplayıp etiketleme işlemini gerçekleştirmeden robotları yeni görevler için eğitmektir. NVIDIA’nın son araştırma çalışmaları, bu zorluğu üretken yapay zeka, dünya temelli modeller (WFM) gibi NVIDIA Cosmos, ve veri üretim şablonları olan NVIDIA Isaac GR00T-Mimic ve GR00T-Dreams aracılığıyla çözümler sağlamayı amaçlamaktadır.
Bu NVIDIA Robotics Research and Development Digest (R2D2) yayını, dünya temelli modeller kullanılarak ölçeklenebilir sahte veri üretim ve robot model eğitim süreçlerini nasıl güçlendirdiğine dair araştırmaları kapsamaktadır. Bahsedilen bazı öne çıkan araştırmalar şunlardır:
- DreamGen: NVIDIA Isaac GR00T-Dreams şablonunun araştırma temelidir.
- GR00T N1: Robotların gerçek, insan ve sahte verilerden çeşitli görevler ve gövde yapıları arasında genel beceriler öğrenmesini sağlayan açık bir temel modeldir.
- Videolardan Latent Eylem Ön Eğitim: Manuel eylem etiketleri gerektirmeden geniş ölçekli videolardan robotla ilgili eylemleri öğrenen bir denetimsiz yöntemdir.
- Sim ve Gerçek Co-Training: Simülasyonda ve gerçek dünyada robot verilerini birleştirerek daha sağlam ve uyumlu robot politikaları geliştiren bir eğitim yaklaşımıdır.
Dünya Temelli Modellerin Rolü
Cosmosdünya temelli modeller (WFM), milyonlarca saatlik gerçek dünya verisi üzerinde eğitilmiş ve robotların ve otonom araçların gelecekteki olayları tahmin edebilmesini sağlamaktadır. Bu öngörü yeteneği, sahte veri üretim hatlarının önemli bir bileşeni olarak, çeşitli ve yüksek kaliteli eğitim verilerinin hızlı bir şekilde oluşturulmasını kolaylaştırır. Bu yaklaşım, robot öğrenimini büyük ölçüde hızlandırmakta ve modelin sağlamlığını artırmaktadır. Böylece, gelişim süresi aylarca süren manuel çabadan sadece saatlere indirilir.
DreamGen: Verimli Veri Üretimi
DreamGen, robot öğrenimi için büyük ölçekli insan teleoperasyon verilerinin toplanmasında ortaya çıkan yüksek maliyet ve iş gücü ihtiyacını karşılayan bir sahte veri üretim hattıdır. Bu sistem, NVIDIA Isaac GR00T-Dreams için bir temel oluşturur ve dünya temelli modeller aracılığıyla geniş sahte robot hareket verileri üretir.
Geleneksel robot temelli modeller, her yeni görev ve ortam için kapsamlı manuel gösterimler gerektirir ki bu da ölçeklenebilir değildir. Simülasyon tabanlı alternatifler genellikle simülasyondan gerçek dünyaya geçişte sorunlar yaşar ve yoğun bir şekilde manuel mühendislik gerektirir.
DreamGen, dünya temelli modeller kullanarak minimal insan müdahalesi ile gerçekçi ve çeşitli eğitim verileri oluşturma becerisi sayesinde bu zorlukların üstesinden gelmektedir. Bu yöntem, robot öğreniminin ölçeklenebilir olmasını sağlarken pek çok görev, ortam ve robot çeşitliliği arasında güçlü genelleme yapabilmesine olanak tanır.

DreamGen iş akışı dört ana adımda gerçekleştirilir:
- Dünya temelli modeli sonrası eğitim:Cosmos-Predict2 gibi bir dünya temelli modeli, az sayıda gerçek gösterimle hedef robota uyarlanır. Cosmos-Predict2, metinden yüksek kaliteli görüntüler (metinden görüntüye) ve görüntü veya videolardan görsel simülasyonlar (videodan dünyaya) oluşturabilir.
- Sahte videolar oluşturma: Post-eğitim modelini, yeni görevler ve ortamlardan görüntü ve metin istemleri kullanarak çeşitli, fotoğrafik robot videoları üretmek için kullanın.
- Takiplenmiş eylemleri çıkarma: Bu videolardan eylem dizilerini (nöral hareketler) elde etmek için bir latent eylem modeli veya ters dinamik modeli (IDM) uygulanır.
- Robot politikalarını eğitme: Elde edilen sahte hareket dizileri kullanılarak, robotları yeni davranışları gerçekleştirebilen ve daha önce görülmemiş senaryolara genelleme yapabilen görsel-motor politikaları eğitilir.

DreamGen Bench: Değerlendirme Aracı
DreamGen Bench, video üretken modellerinin belirli robot yapılarına nasıl uyum sağladığını değerlendirirken, katı cisim fiziğini içselleştirme ve yeni nesne, davranış ve ortamlarla genelleme ölçümünde kullanılan özel bir değerlendirme aracıdır. Bu değerlendirme, dört önde gelen dünya temelli modelin – NVIDIA Cosmos, WAN 2.1, Hunyuan ve CogVideoX – performansını karşılaştırır ve iki kritik metriği ölçer:
- Talimat izleme: Oluşturulan videoların, görev talimatlarını ne kadar doğru bir şekilde yansıttığını değerlendirir (örneğin, “soğanı al”) ve bu değerlendirmeyi Qwen-VL-2.5 gibi görsel dil modelleri ve insan değerlendirmeciler ile yapar.
- Fizik izleme: Gerçek dünya fiziğine uyduğu için VideoCon-Physics ve Qwen-VL-2.5 gibi araçlar kullanarak fiziksel gerçekçiliği nicelendirir.
Şekil 3’te görüldüğü gibi, DreamGen Bench’de daha yüksek puan alan modeller – daha gerçekçi ve talimatları izleyen sahte veriler üretenler – gerçek manipülasyon görevlerinde robotlar üzerinde daha iyi performans sergilemektedir. Bu olumlu ilişki, daha güçlü dünya temelli modellere yatırım yapmanın, yalnızca sahte eğitim verilerinin kalitesini artırmakla kalmayıp, aynı zamanda uygulamada daha yetenekli ve uyumlu robotlara da dönüştüğünü göstermektedir.

NVIDIA Isaac GR00T-Dreams: Yeni Bir Çığır Açan Çalışma
Isaac GR00T-Dreams, DreamGen araştırmasına dayanan robot eylemlerinin geniş veri setlerini üretmek için bir iş akışıdır. Bu veri setleri, gerçek dünyanın robot hareket verilerini toplamak yerine fiziksel robotları eğitmek için kullanılır ve önemli bir zaman ve emek tasarrufu sağlar.
GR00T-Dreams, farklı görevler ve ortamlar için veri üretmek üzere Cosmos Predict2 WFM ve Cosmos Reason’i kullanarak verilerini üretmektedir. Cosmos Reason modelleri, kullanıcının istemlerine fiziksel olarak sağlam yanıtlar üretebilen bir multimodal büyük dil modeli (LLM) içermektedir.
Genel Becerilere Sahip Robotlar İçin Eğitim Modelleri ve İş Akışları
Görsel dil eylem (VLA) modelleri, WFM’lerden üretilen veriler ile yeniden eğitim edilebilir; böylece henüz görülmemiş ortamlarda yenilikçi davranışlar ve işlemler gerçekleştirebilmektedirler.
NVIDIA Araştırma, GR00T-Dreams şablonunu kullanarak sahte eğitim verileri üretmeyi başardığı için, GR00T N1.5 isimli bir güncelleme, yalnızca 36 saat içinde geliştirilmiştir. Oysa bu süreç normalde üç ay boyunca sürmektedir.
GR00T N1, genel amaçlı insansı robotlar için geliştirilmiş ilk açık modeldir ve bu alanda büyük bir atılım teşkil etmektedir. İnsanın bilişsel yapısını temel alarak tasarlanan çift sistem mimarisine sahip GR00T N1, robotların talimatları anlamasını, çevrelerini algılamasını ve karmaşık çok aşamalı görevleri gerçekleştirmesini sağlayan bir yapıdır.
GR00T N1, etiketlenmemiş insan videolarından öğrenmek için kullanılan LAPA gibi teknikleri ve sim ve gerçek arasında co-eğitim yaklaşımını uygulayarak, daha güçlü genelleme konusunda destek sağlamaktadır. Tüm bu yeniliklerin birleşimi, GR00T N1’in sadece talimatları takip etmesini değil, aynı zamanda karmaşık ve sürekli değişen ortamlarda neyi başardığını da göstermektedir.
GR00T N1.5, özgün GR00T N modelini geliştirerek, çeşitli gerçek, simüle edilmiş ve DreamGen ile üretilen sahte veri ile eğitim yapılmış bir görsel dil modelini içermektedir.
Modelin daha iyi yapılandırılması ve veri kalitesindeki iyileşmeler sayesinde, GR00T N1.5, daha yüksek başarı oranları, daha iyi dil anlama yeteneği ve yeni nesneler ve görevler arasında daha güçlü bir genelleme kapasitesi sunmaktadır ve böylece ileri düzey robot manüplasyonları için daha sağlam ve uyumlu bir çözüm haline gelmektedir.
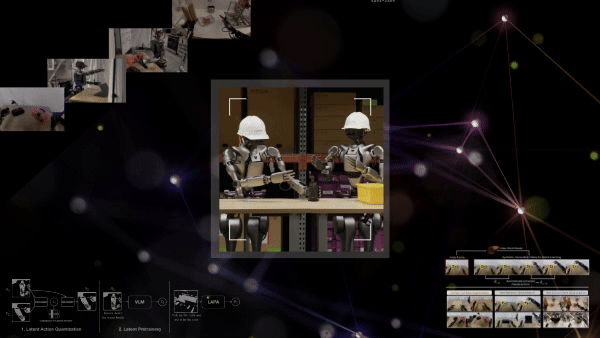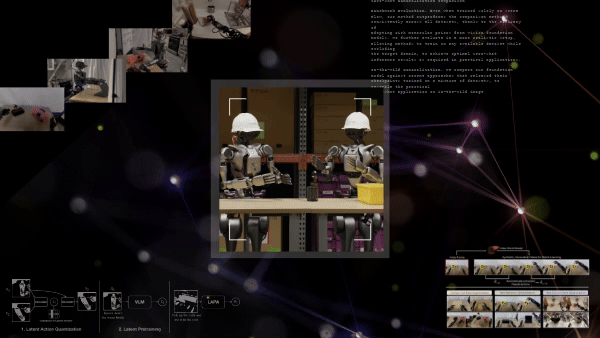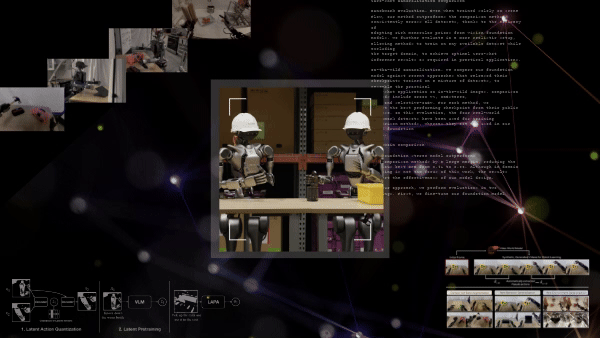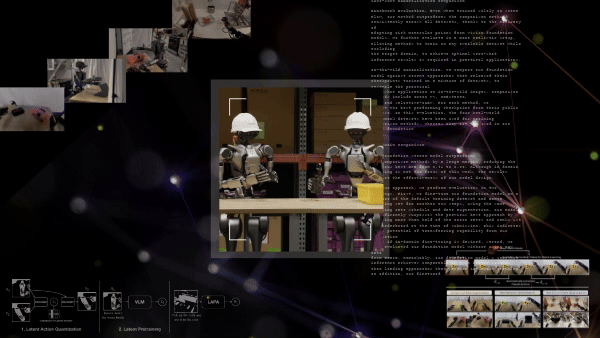
Videolardan Latent Eylem Ön Eğitimi
Latent Action Pretraining for general Action models (LAPA), pahalı yapılandırılmış robot eylem verisine gereksinimi ortadan kaldıran denetimsiz bir ön eğitim yöntemidir. Bu yöntem, büyük, etiketlenmemiş veri setlerine gereksinim duymadan, 181,000’den fazla etiketlenmemiş internet videosu kullanarak etkili temsiller öğrenmeyi sağlar.
LAPA, gerçek dünya görevlerinde gelişmiş modellere %6.22 oranında bir performans artışı sağlarken, %30’dan fazla bir ön eğitim verimliliği sunmaktadır; bu da ölçeklenebilir ve sağlam robot öğrenimini erişilebilir ve verimli kılmaktadır.
LAPA iş akışı üç aşamadan oluşur:
- Latent eylem kuantizasyonu: Bir Vector Quantized Variational AutoEncoder (VQ-VAE) modeli, video kareleri arasındaki geçişleri analiz ederek, ayrıntılı “latent eylemler” öğrenir ve atomik davranışların bir kelime dağarcığını oluşturur (örneğin, kavrama, dökme). Latent eylemler, karmaşık robot davranışlarını veya hareketlerini özetleyen düşük boyutlu, öğrenilmiş temsillerdir.
- Latent ön eğitim: İlk aşamadaki latent eylemleri video gözlemleri ve dil talimatları temelinde tahmin etmek için bir VLM üzerinde davranış taklit yöntemiyle ön eğitim uygulanır.
- Robot sonrası eğitim: Önceden eğitilmiş model daha sonra, gerçek robotlara uygun hale getirmek için küçük bir etiketli veri seti ile son eğitim sürecinden geçirilir.

Sim ve Gerçek Co-Training İş Akışı
Robot politikalarının eğitimi, iki önemli zorlukla karşı karşıyadır: gerçek dünya verisinin toplanmasının yüksek maliyeti ve yalnızca simülasyonda eğitilen politikaların gerçek fiziksel ortamlarda iyi performans gösterememesi.
Sim ve Gerçek Co-Training iş akışı, az sayıda fiziksel robot gösterimini büyük miktarda simülasyon verisi ile birleştirerek bu sorunları ele alır. Bu yaklaşım, sağlam politikaların eğitilmesine olanak tanırken maliyetleri etkin bir şekilde düşürmekte ve gerçeğe yakınlık farkını azaltmaktadır.

Bu iş akışındaki temel adımlar şunlardır:
- Görev ve sahne kurulumu: Gerçek dünya görevlerinin kurulması ve görev bağımsız ön simülasyon veri setlerinin seçilmesi.
- Veri hazırlığı: Bu aşamada, fiziksel robotlardan gerçek dünya gösterimleri toplanırken, ek simüle edilmiş gösterimler de üretilir. Bunlar, gerçek görevlerle yakından örtüşen “dijital akrabalar” olarak ve çeşitli, görev bağımsız ön simülasyonlar olarak üretilir.
- Koordineli eğitim parametre ayarı: Bu farklı veri kaynakları, optimize edilmiş bir ko-training oranında birleştirilir ve en iyi hizalama ile simülasyon çeşitliliğini artırmayı hedefler. Son aşama, hem gerçek hem simüle edilmiş veri kullanarak eğitim ve politika ko-training süreçlerinin gerçekleştirilmesidir.

Şekil 7’de görüldüğü gibi, gerçek dünya gösterim sayısının artması, yalnızca gerçek veri ile eğitilmiş ve co-trained politikalar için başarı oranlarını artırmaktadır. 400 gerçek gösterimle bile, co-trained politika, gerçek verilerle eğitilen politika ile kıyaslandığında, ortalama %38 daha iyi bir performans göstererek, co-training sürecinin veri açısından zengin ortamlarda dahi faydalı kalabildiğini göstermektedir.

Ecosystem Adoptasyonu
Öne çıkan kuruluşlar, NVIDIA araştırmalarının sunduğu bu iş akışlarını benimseyerek gelişimleri hızlandırmaktadır. GR00T N modellerinin erken benimseyicileri arasında yer alan firmalar şunlardır:
- AeiRobot: Modelleri, karmaşık alma ve yerleştirme görevleri için endüstriyel robotuzu doğal dil ile anlamalarını sağlamak amacıyla kullanıyor.
- Foxlink: Modelleri, endüstriyel robot kollarının esnekliğini ve verimliliğini artırma amacıyla değerlendiriyor.
- Lightwheel: Modeller sayesinde, fabrikalarda insansı robotların daha hızlı bir şekilde devreye alınması için sahte verileri doğruluyor.
- NEURA Robotics: Modelleri, ev otomasyon sistemlerinin geliştirilmesini hızlandırmak için değerlendiriyor.
Başlamak İçin Kaynaklar
Aşağıda bu konulara dalmak için bazı kaynaklar bulunmaktadır:
- DREAMGEN:Proje Web Sitesi, Makale, GitHub
- NVIDIA Isaac GR00T-Dreams:GitHub
- NVIDIA Isaac GR00T N1.5:Proje Web Sitesi, Makale, Model, GitHub
- Videolardan Latent Eylem Ön Eğitimi:Proje Web Sitesi, Makale, Model, GitHub
- Sim ve Gerçek Co-Training:Proje Web Sitesi, Makale
- NVIDIA Cosmos:Cosmos Predict2, Cosmos Reason, Cosmos Transfer, Cosmos benchmark
Bu yazı, geliştiricilere NVIDIA Araştırmaları’nın fiziksel AI ve robotik uygulamalardaki en son yenilikleri hakkında derinlemesine bilgi sağlamak amacıyla hazırlanan NVIDIA Robotics Research and Development Digest (R2D2) serisinin bir parçasıdır.
Daha fazla bilgi almak için NVIDIA Araştırma‘yı ziyaret edebilir ve bültene kaydolabilirsiniz. Ayrıca YouTube, Discord ve geliştirici forumlarıını takip edebilirsiniz. Robotik yolculuğunuza başlamak için ücretsiz NVIDIA Robotik Temeller kurslarına kaydolabilirsiniz.
Teşekkürler
Bu yazıda bahsedilen araştırmalara katkıda bulunanlara: Johan Bjorck, Lawrence Yunliang Chen, Nikita Chernyadev, Yu-Wei Chao, Bill Yuchen Lin, Lin Yen-Chen, Linxi ‘Jim’ Fan, Dieter Fox, Yu Fang, Jianfeng Gao, Ken Goldberg, Fengyuan Hu, Wenqi Huang, Spencer Huang, Zhenyu Jiang, Byeongguk Jeon, Sejune Joo, Jan Kautz, Joel Jang, Kaushil Kundalia, Kimin Lee, Lars Liden, Zongyu Lin, Ming-Yu Liu, Loic Magne, Abhiram Maddukuri, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Baolin Peng, Scott Reed, Reuben Tan, You Liang Tan, Jing Wang, Qi Wang, Guanzhi Wang, Zu Wang, Jianwei Yang, Seonghyeon Ye, Yuke Zhu, Yuqi Xie, Jiannan Xiang, Zhenjia Xu, Yinzhen Xu, Xiaohui Zeng, Kaiyuan Zheng, Ruijie Zheng, Luke Zettlemoyer


