
Hızla gelişen retrieval augmented generation (RAG) tabanlı soru-cevap LLM iş akışları, yeni sistem mimarilerinin ortaya çıkmasına yol açmıştır. NVIDIA’daki çalışmalarımız, yapay zekanın iç operasyonlarımızda kullanılması için sistem yetenekleri ile kullanıcı beklentileri arasında bir uyum bulmamıza yardımcı oldu.
Kullanıcıların amaçları veya kullanım durumları ne olursa olsun, genellikle RAG dışı görevleri gerçekleştirebilme yeteneğine sahip olmak istediklerini tespit ettik. Örneğin, belge çevirisi yapmak, e-postaları düzenlemek veya hatta kod yazmak gibi işlemleri gerçekleştirme arzusu taşıyorlar. Basit bir RAG uygulaması, her mesaj için bir geri alma süreci çalıştırıldığında, gereksiz sonuçların dahil edilmesi nedeniyle aşırı token kullanımı ve istenmeyen gecikmelere neden olabiliyor.
Ayrıca, kullanıcıların, uygulama iç veriye erişmek üzere tasarlanmış olsa bile, web arama ve özetleme yeteneğine sahip olmaktan büyük bir memnuniyet duyduğunu fark ettik. Bu ihtiyacı karşılamak için Perplexity’nin arama API’sini kullandık.
Bu yazıda, bu sorunları çözmek için bir temel mimari sunuyoruz. Yönlendirme ve çok kaynaklı RAG kullanarak, geniş bir soru yelpazesine yanıt verebilen bir sohbet uygulaması geliştirdik. Bu, NVIDIA’da satış operasyonlarımızı desteklemek için üretime aldığımız uygulamanın sadeleştirilmiş bir versiyonudur. Daha fazla bilgi için, NVIDIA’nın Generative AI Örnekleri GitHub repo’suna göz atabilirsiniz.
LLM Dağıtımı için NIM Mikroservisleri
Projemiz, birkaç model çevresinde oluşturulan NVIDIA NIM mikroservisleri üzerine inşa edilmiştir. Bu modellerden bazıları şunlardır:
- Meta’nın Llama-3.1-70b-instruct
- NVIDIA’nın nv-embed-v1 metin gömme için
- Mistral’ın nv-rerankqa-mistral-4b-v3 yeniden sıralama için
Makine öğrenimi mühendisleri veya LLM çıkarım uzmanları olmadan, sadece birkaç saat içinde NVIDIA A100 donanımlı bir düğümde (8 GPU) çalışan bir NIM konteyneri ile kendi llama-3.1-70b-instruct instance’ımızı talep edip dağıttık. Bu durum, bazı kurumsal LLM API’leri ile yaşadığımız erişim ve gecikme sorunlarını aşmamıza yardımcı oldu.
NIM API’lerini denemek için build.nvidia.com adresinden bir hesap oluşturabilir ve API anahtarı alabilirsiniz. Bu projede API anahtarını kullanmak için, proje dizininde bir .env dosyasında mevcut olduğundan emin olun. NVIDIA modelleri ve API’leri için LlamaIndex bağlantıları Python paketillama-index-llms-nvidia‘da mevcuttur. NIM tabanlı LLM dağıtımına ilişkin performans avantajları hakkında daha fazla bilgi için Optimizing Inference Efficiency for LLMs at Scale with NVIDIA NIM Microservices dokümanına göz atabilirsiniz.
LlamaIndex Workflow Olayları
Uygulamamızın ilk versiyonu, vektör veritabanı ile desteklenen bir konuşma AI asistanı dağıtımına olanak tanıyan LlamaIndex’in ChatEngine sınıfından yararlanmıştı. Ancak daha fazla esneklik ve bağlam zenginliği sağlamak için ek adımlar eklemek istediğimizde daha fazla uzlaşabilirlik bulduk.
LlamaIndex Workflow olayları, uygulamanın yürütme akışını kontrol etmek için gereken adım tabanlı, olay odaklı yaklaşımı sağladı. Bu sayede uygulamayı daha hızlı ve kolay bir şekilde uzatmamız mümkün oldu.
Chainlit ile Oyun Değiştiren Bir Kullanıcı Arayüzü
Chainlit, LLM tabanlı sohbet uygulamamız için mükemmel bir çözüm oldu. Progres göstergeleri ve adım özetleri sağlarken, LlamaIndexCallbackHandler otomatik izleme sağlıyor. Her bir LlamaIndex Workflow olayını ortaya çıkarmak için bir Step dekoratörü kullandık.
Chainlit’in kurumsal kimlik doğrulama ve PostgreSQL veri katmanı desteği de üretim için kritik öneme sahipti.
Proje Ortamını Kurma
Bu projeyi dağıtmak için, NVIDIA Generative AI Örnekleri dizininden bir klon oluşturun ve bir sanal Python ortamı oluşturun. Ortamı oluşturduktan sonra bağımlılıkları yüklemek için aşağıdaki komutları çalıştırın:
mkdir .venv
pip -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Yapılandırma
Bağımlılıkları yükledikten sonra, proje dizininizin en üst düzeyinde .env dosyasının aşağıdaki değerlerle mevcut olduğundan emin olun:
NVIDIA_API_KEY: Gerekli. NVIDIA’nın hizmetleri için bir API anahtarı alabilirsiniz. Bunun için build.nvidia.com sitesini ziyaret edin.PERPLEXITY_API_KEY. İsteğe bağlı. Sağlanmazsa, uygulama Perplexity’nin arama API’sını kullanmadan çalışabilir. Perplexity için bir API anahtarı almak için yönergeleri takip edin.
Proje Yapısı
Proje kodunu ayrı dosyalara yapılandırdık:
- LlamaIndex
Workflow(workflow.py): Sorguları yönlendiren ve çoklu kaynaklardan yanıtları toplayan modül. - Belge alma (
ingest.py): PDF’leri analiz etmek ve yüklemek için LlamaIndex’inSimpleDirectoryReaderkullanarak Milvus Lite veritabanına belgeleri yükler. - Chainlit uygulaması (
chainlit_app.py): Olaylar tarafından tetiklenen işlevleri içerir, açıkçaon_messageana işlevi kullanıcı mesajlarında etkinleştirilir. - Yapılandırma (
config.py): Farklı model türleri ile oynamak için varsayılan değerleri düzenleyebilirsiniz. Buradan yönlendirme ve sohbet tamamlanması için farklı modelleri seçip, geçmiş sohbet mesajlarından kullanılan sayısını ve Perplexity için web arama ve özetleme işlevinde kullanılacak model türünü belirleyebilirsiniz.
Ayrıca prompts.py dosyasında belirtilen istemleri, kullanım durumunuza uygun olacak şekilde ayarlayabilirsiniz.
Temel İşlevselliği Geliştirme
Bu uygulama, Chainlit aracılığıyla LlamaIndex ve NIM mikroservislerini entegre ediyor. Bu mantığı uygulamanın nasıl gerçekleştirileceğine dair aşağıdaki adımları tartışacağız:
- Kullanıcı arayüzünü oluşturma
Workflowolayını uygulama- NIM mikroservislerini entegre etme
Kullanıcı Arayüzünü Oluşturma
Proje, chainlit_app.py dosyasındaki Chainlit uygulamasıyla başlıyor. set_starter işlevinde ilk soruları önceden doldurulmuş, tıklanabilir Starter nesneleri listesi oluşturarak kullanıcıları yönlendirebilirsiniz. Bunlar, kullanıcıya belirli özelliklere veya sorulara yönlendirme yapmayı kolaylaştırır.
Ana sohbet işlevi, cl.user_session değişkenini kullanarak mesaj geçmişini yönetir. Bu durum, Chainlit’in konuşma geçmişini göstermesi için gerekli değildir ancak bize durumu istemci tarafında tutma imkanı sağladı.
Bu yaklaşım, prototiplemeyi daha basit hale getirdi ve geleneksel bir kullanıcı-ön yüzü arka uç uygulamasına geçiş yapmayı kolaylaştırdı. LlamaIndex ChatEngine’i kullanmanın karmaşıklığı, REST API dağıtımını zorlaştırıyordu.
Workflow Olayını Uygulama
RAG mantığı, workflow.py içindeki QueryFlow sınıfında bulunuyor ve bu sınıf bir dizi adım içeriyor. Her bir adım, kendi belirttiği olaylar gerçekleştiğinde tetikleniyor. Adımlar arasında düğümlerin listelerini geçmek, akışın düzenlenmesi açısından kolay bir yöntem sağladı.
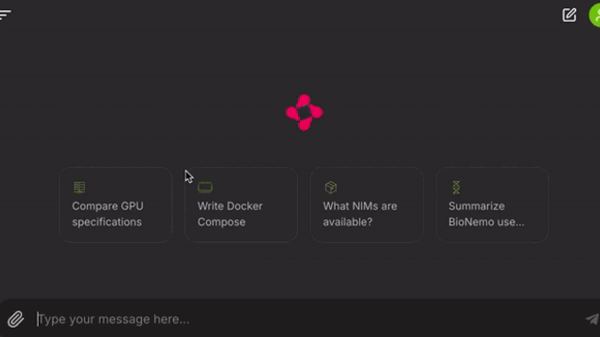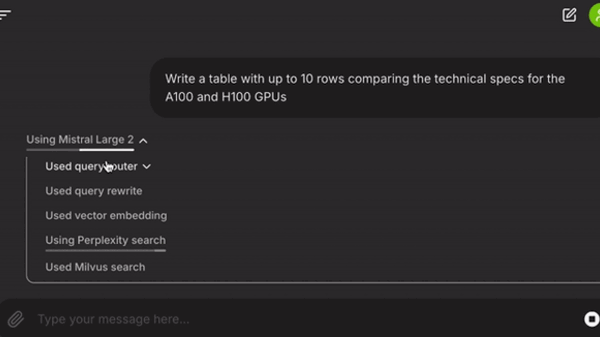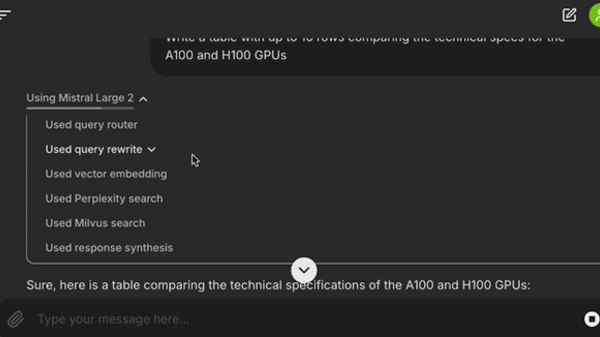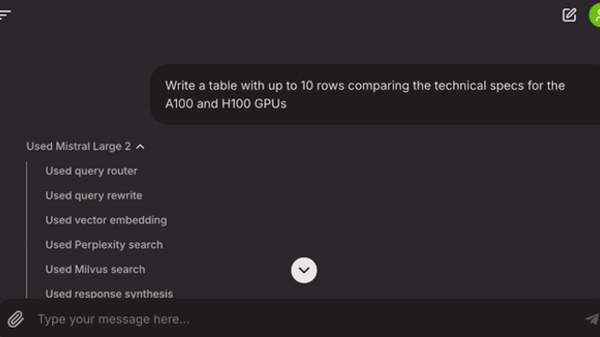
İşte Workflow adımları:
workflow_start: Kullanıcının sorgusunu ve sohbet geçmişini akışın bağlamına ekler. RAG ve RAG dışı sorgular arasında yönlendirme yapar.rewrite_query: Kullanıcı sorgusunu arama sonuçlarını iyileştirmek için dönüştürür.embed_query: Dönüştürülmüş sorgu için bir vektör gömme oluşturur.milvus_retrieve: Vektör gömme için vektör arama gerçekleştirir.pplx_retrieve: Perplexity arama API’sını kullanarak web arama sonuçlarını alır.collect_nodes: Milvus ve Perplexity’den gelen sonuçları birleştirir.response_synthesis: Önceki sohbet geçmişi bağlamı ve alınan belgelerle bir yanıt dizesi oluşturur.
NIM Mikroservislerini Entegre Etme
NVIDIA NIM mikroservislerini LLM ve gömme işlevselliği için kullanmak hızlıydı. llama-index-llms-nvidia ve llama-index-embeddings-nvidia paketlerinden mevcut bağlantılar sayesinde bu entegre işlemi sağladık.
Birçok model seçeneği arasından, sorguları yönlendirmek için Meta’nın meta/llama-3.1-8b-instruct gibi hızlı çalışan bir modeli tercih edebiliriz. Ayrıca daha yüksek performans arayan kullanıcılar için meta/llama-3.1-405b-instruct iyi bir alternatif olarak değerlendirilebilir.
NIM mikroservislerinin büyük bir avantajı, kendi kendine yönetilen LLM çıkarım dağıtımına geçmek istendiğinde sadece base_url parametresini ayarlamak gerektiğidir; bu, kod değişikliği gerektirmiyor!
Ek Özellikler
Bu yazının kapsamının dışındaki birkaç ek özellik, değer katmak için eklenebilir:
- Multimodal gözleme ile görsel-dil modelleri kullanarak tablo okuma, optik karakter tanıma ve resim başlıklandırma yapılabilir.
- Kullanıcı sohbet geçmişi için Chainlit’in Postgres bağlantısı kullanılabilir.
- RAG yeniden sıralama mümkündür.
- Alıntı ekleme özellikleri eklenebilir.
- Hata yönetimi ve zaman aşımı yönetimi ile uygulamanın güvenilirliği artırılabilir.
NVIDIA ve LlamaIndex Geliştirici Yarışmasına Katılın
Bu yazının, size generatif AI hakkında daha fazla bilgi edinmenizde faydalı bir kaynak olmasını umuyoruz. Eğer bu projeden ilham alıyorsanız, kendi AI destekli çözümlerinizi geliştirmek için NVIDIA ve LlamaIndex Geliştirici Yarışması’na katılmayı düşünebilirsiniz. Ücretli ödüller, NVIDIA GeForce RTX 4080 SUPER GPU ve DLI kredileri kazanma şansınız olabilir.
Daha fazla bilgi edinmek veya benzer uygulamaları keşfetmek için buradan kodu inceleyebilir veya NVIDIA’nın GenerativeAI Örnekleri GitHub repo’sundaki diğer referans uygulamalarını deneyebilirsiniz.