


Bir yazılım geliştiricisi, eski bir donanım olan 2005 model PowerBook G4 üzerinde modern bir büyük dil modelinin (LLM) çalıştırılabileceğini kanıtladı, ancak tüketicilerin beklediği hızların çok altında.
Yapay zeka projeleri, genellikle yerel olarak sorguları işlemek için güçlü bir cihaz gerektirir. Bu nedenle, iPhone 16 neslinin en yeni A serisi çipleri gibi ancak yeterince güçlü olan yeni bilgisayarlar ve işlemciler yapay zeka uygulamaları için kullanılmaktadır.
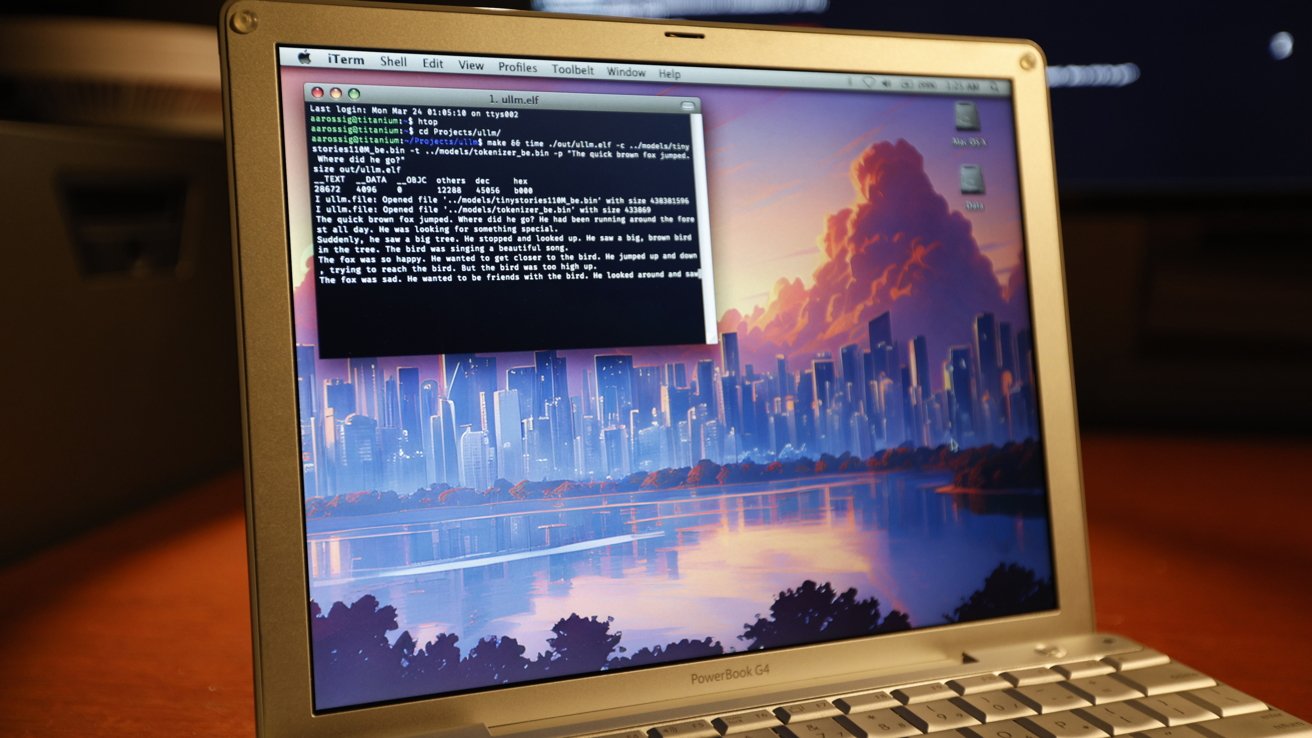
The Resistor Network‘te yayımlanan bir blog yazısında, Andrew Rossignol — MacRumors’tan Joe Rossignol’ün kardeşi — eski donanımda modern bir LLM çalıştırma konusundaki çalışmasını aktarıyor. Rossignol’un kullanımına sunulan donanım, 1.5 GHz işlemciye, 1 GB belleğe ve 32-bit adres uzayı gibi mimari sınırlamalara sahip bir 2005 PowerBook G4.
Rossignol, Llama2 LLM’sini çalıştırmak için tek bir vanilla C dosyası ile llama2.c projesini inceledi ve projeyi geliştirmek için ana kütüphaneyi fork’ladı.
Bu geliştirmeler, sistem işlevleri için sarmalayıcılar oluşturmayı, kodu halka açık bir API ile bir kütüphane haline getirmeyi içeriyordu. Sonunda, projeyi PowerPC Mac’lerde çalışabilir hale getirdi. Bu, “büyük sonlu” işlemciyle ilgili sorunları içeriyordu; model kontrol noktaları ve belirteçlerin, “küçük sonlu” işlemciler kullanmayı beklediğini göz önünde bulundurmak gerekiyordu.
Hız Aşırı Sınırlı
llama2.c projesinin önerisi, özel donanım hızlandırması olmadan çıktılar üretme şansını artırmak için TinyStories modelini kullanmaktı. Testler genellikle 15 milyon parametreye sahip (15M) model versiyonu ile gerçekleştirildi ve daha sonra 110M versiyonuna geçildi; daha büyük olanlar adres alanı için fazla büyük oluyordu.
Bir modeldeki parametre sayısı, modelin karmaşıklığını artırabilir. Bu nedenle, kullanıcıya doğru bir yanıt üretebilmek için mümkün olduğunca çok parametre kullanmaya çalışmak önemlidir; ancak yanıt hızı kaybedilmemelidir. Projede aşırı sıkışık sınırlamalar olduğu için, yeterince kullanılabilir boyutta modellere yönelmek gerekiyordu.
PowerBook G4 projesinin performansını değerlendirmek için, bir Intel Xeon Silver 4216 tek çekirdek işlemcisi ile karşılaştırma yapıldı. Benchmark testi, bir sorgunun 26.5 saniyede sonuçlandığını ve 6.91 token/saniye hızında çalıştığını gösterdi.
PowerBook G4 üzerinde aynı kod çalıştı, ancak sonuç süresi çok daha yavaş, yani 4 dakika oldu; bu da tek Xeon çekirdeğinden dokuz kat daha yavaş bir performans. Daha fazla optimizasyonla, AltiVec gibi vektör uzantıları kullanarak, bir buçuk dakika kadar daha hızlı sonuç elde edildi; böylece PowerBook G4, sadece sekiz kat daha yavaş hale geldi.
Sonuçlar Eğlenceli ve Öğretici
Seçilen modeller, “neşeli çocuk hikâyeleri” üretmeyi başardı. Bu, hata ayıklama sırasında ruh halini yükseltti.
Bir Gelecek Olarak Eski Donanım
Test edilen donanım üzerinde daha fazla performans elde edilmesi pek mümkün görünmüyor; çünkü 32-bit kullanımı ve maksimum 4 GB adreslenebilir bellek sınırları gibi sınırlamaları var. Kuantizasyon ile kıyaslanabilse de, adres alanı çok dar.
Projeye şu anda belki de en iyi geldiği yerden devam edeceğini belirten Rossignol, bu deneyimin kendisi için LLM’ler ve nasıl çalıştıkları hakkında iyi bir girişim olduğunu ekliyor. Ayrıca “Xeon’dan 15 yıl önceki bir bilgisayarın bunu başarmış olması oldukça etkileyici” diye de ekliyor.
Bütün bunlar, eski donanımların hala yapay zeka ile kullanılabileceği umudunu veriyor. Ancak keskin yazılım gelişmelerinin, modern donanım kadar etkili bir şekilde çalışmasını beklemek, bazı sınırlamalar ve çok daha düşük hızlar gerektiriyor.
Modern donanım satın almayı gerektiren zorluklar devam edecek. Ancak, LLM ve yapay zeka üzerinde çalışanlar için, PowerBook G4 gibi projeler ile denemeler yapmak hâlâ öğretici ve keyif verici olabilir.




