


NVIDIA’nın TensorRT-LLM kütüphanesi, spekülatif kodlama desteği ile toplam token veriminde %300’ün üzerinde bir yükseliş sağladı. TensorRT-LLM, NVIDIA GPU’ları üzerinde birçok popüler büyük dil modelleri (LLM) için hızlı çıkarım desteği sunan açık kaynaklı bir kütüphanedir. Tekil GPU ve tek düğüm çoklu GPU desteği ekleyerek, kütüphane, yaratıcı AI uygulamaları için en iyi performansı sağlayacak şekilde optimizasyonlarını genişletmektedir.
TensorRT-LLM, NVIDIA TensorRT derin öğrenme derleyicisini kullanmaktadır. Farklı dikkat mekanizmaları için en son optimize edilmiş çekirdekleri içermekte ve LLM modeli yürütme süreci için ön ve son işleme adımlarını ayrıca çoklu GPU/çoklu düğüm iletişim ilkelere basit bir açık kaynaklı Python API’sinde bir araya getirmektedir. Bu kütüphane, GPU’lar üzerinde çarpıcı LLM çıkarım performansı sunmaktadır.
Spekülatif kodlama, ayrıca spekülatif örnekleme olarak da bilinir, küçük bir ek hesaplama maliyeti ile gelecek tokenların birkaçını spekülatif olarak üreterek, hedef modelin çıkış kalitesini doğrulamak için yerleşik bir doğrulama adımı gerçekleştirmesini sağlamaktadır. Bu süreç, toplam verim artışını beraberinde getirir.
Bu yazıda, TensorRT-LLM ile spekülatif kodlama işleminin nasıl yapılandırılacağı adım adım açıklanacaktır. Diğer optimizasyonlar, farklı modeller ve çoklu GPU yürütmesi hakkında daha fazla bilgi için TensorRT-LLM örnekleri listesini inceleyebilirsiniz.
Spekülatif Kodlama ile Verim Artışı Elde Etme
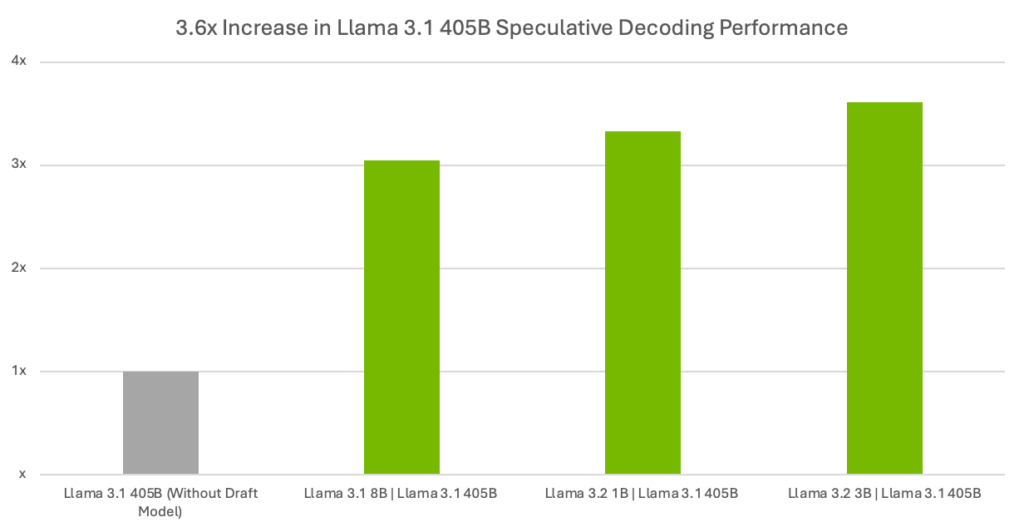
Tablo 1 ve Şekil 1, spekülatif kodlama kullanılmadığında (yani taslak model yokken) Llama 3.1 405B hedef modeli ile farklı boyutlarda taslak modeller arasında token verimindeki farkı göstermektedir.
| Verim Performansı – Çıktı Token/SaniyeDört NVIDIA H200 Tensor Core GPU ile | ||||
| Taslak | Hedef Modeller | Llama 3.2 1B | Llama 3.1 405B | Llama 3.2 3 | Llama 3.1 405B | Llama 3.1 8B | Llama 3.1 405B | Llama 3.1 405B(taslak model olmadan) |
| Token/Saniye | 111.34 | 120.75 | 101.86 | 33.46 |
| Hızlanmalar (taslak modeller ile karşılaştırıldığında) | 3.33x | 3.61x | 3.04x | N/A |
Veriler 18/11/2024 tarihinde ölçülmüştür. Çıktı token/saniye, ilk tokenın üretilmesi için geçen süre dahil – tok/s = toplam üretilen token / toplam gecikme. DGX H200, 4 GPU, TensorRT Model Optimizasyon sürümü 0.21 (ön sürüm), TensorRT-LLM sürümü 0.15.0.dev.
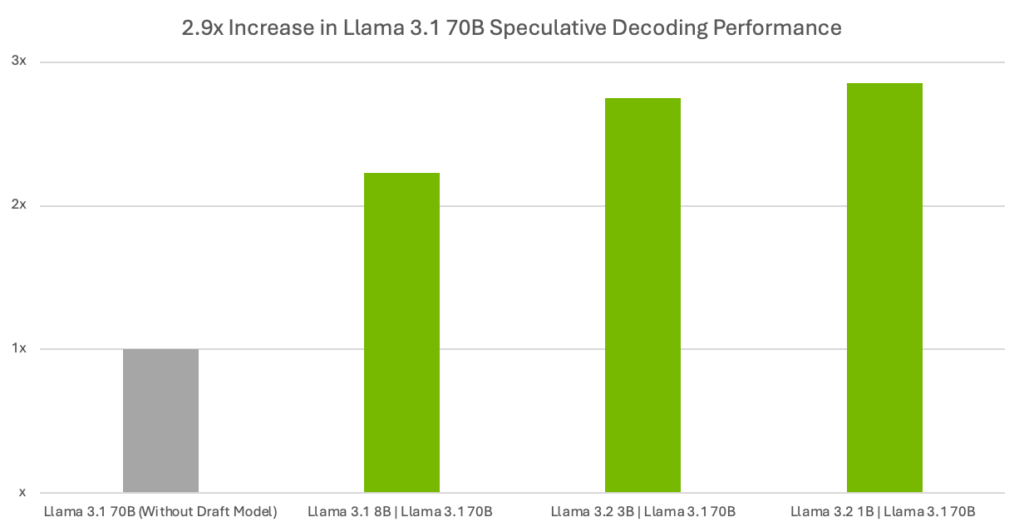
Tablo 2 ve Şekil 2, Llama 3.1 70B hedef modeli ile taslak modeller arasında verim farklarını göstermektedir.
| Verim Performansı – Çıktı Token/SaniyeBir NVIDIA H200 Tensor Core GPU ile | ||||
| Taslak | Hedef Modeller | Llama 3.2 1B | Llama 3.1 70B | Llama 3.2 3 | Llama 3.1 70B | Llama 3.1 8B | Llama 3.1 70B | Llama 3.1 70B (taslak model olmadan) |
| Token/Saniye | 146.05 | 140.49 | 113.84 | 51.14 |
| Hızlanmalar (taslak modeller ile karşılaştırıldığında) | 2.86x | 2.75x | 2.23x | N/A |
Veriler 18/11/2024 tarihinde ölçülmüştür. Çıktı token/saniye, ilk tokenın üretilmesi için geçen süre dahil – tok/s = toplam üretilen token / toplam gecikme. DGX H200, 1 GPU, TensorRT Model Optimizasyon sürümü 0.21 (ön sürüm), TensorRT-LLM sürümü 0.15.0.dev.
TensorRT-LLM Spekülatif Kodlama Kurulumu
Spekülatif kodlama, iki modelin ardışık olarak çalıştırılması ile gerçekleşir: Bir daha küçük ve hızlı taslak model (örneğin: Llama2-7B) ve daha büyük ve yavaş bir hedef model (Llama2-70B). Taslak model, gelecek çıktı tokenlarını spekülatif olarak tahmin eder; hedef model ise bu tokenlardan kaç tanesinin kabul edileceğine karar verir.
Taslak modelin, hedef modelden yeterince hızlı çalışması ve kabul oranının da yeterince yüksek olması durumunda, spekülatif örnekleme süreci daha düşük son kullanıcı gecikmesi sağlar çünkü her bir iterasyonda istatistiksel olarak birden fazla token üretilir (Şekil 3).

Spekülatif Kodlama Eğitimi
Bu eğitim, iki modelin paralel olarak nasıl başlatılacağını ve TensorRT-LLM içinde spekülatif kodlamanın nasıl etkinleştirileceğini adım adım göstermektedir.
Aşağıdaki model kontrol noktalarını Hugging Face’den indirin ve kurulum süreci boyunca kolay erişim için bir dizine koyun:
git lfs install
# Hedef modelleri indir
git clone https://huggingface.co/meta-llama/Meta-Llama-3.1-405B-Instruct
git clone https://huggingface.co/meta-llama/Meta-Llama-3.1-70B-Instruct
# Taslak modelleri indir
git clone https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct
git clone https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct
git clone https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct
Model kontrol noktaları indirildikten sonra, TensorRT-LLM’yi kurun:
# Temel docker imaj ortamını elde edip başlatın (isteğe bağlı).
docker run --rm --ipc=host --runtime=nvidia --gpus all --entrypoint /bin/bash -it nvidia/cuda:12.5.1-devel-ubuntu22.04
# Bağımlılıkları kurun, TensorRT-LLM için Python 3.10 gereklidir
apt-get update && apt-get -y install python3.10 python3-pip openmpi-bin libopenmpi-dev git git-lfs
# Kütüphaneyi fetch edin
git clone -b v0.14.0 https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM
# TensorRT-LLM'nin en son sürümünü yükleyin (ana dal ile ilişkili).
pip3 install tensorrt_llm -U --extra-index-url https://pypi.nvidia.com
# Kurulumu kontrol edin
python3 -c "import tensorrt_llm"
Sonraki adımda, indirilen model kontrol noktalarını taslak ve hedef TRT motorlarına derleyin. Bu motorlar, en iyi doğruluk ve en yüksek verim ile çıkarım yapmak üzere optimize edilmiştir.
cd examples
# 405B hedef ve taslak modellerini 4 H200 üzerinde FP8 hassasiyetle derleme adımları
# FP8 kontrol noktalarını oluşturun
python3 quantization/quantize.py --model_dir --dtype float16 --qformat fp8 --kv_cache_dtype fp8 --output_dir /ckpt-draft --calib_size 512 --tp_size 4
python3 quantization/quantize.py --model_dir= --output_dir=./ckpt-target-405b --dtype=float16 --qformat fp8 --kv_cache_dtype fp8 --calib_size 512 --tp_size 4
# Derleme adımları
# Engine derleme sürecinde önemli bayraklar:# --use_paged_context_fmha=enable, taslak/hedef model için KV cache kullanımını sağladığı için belirtilmelidir.
# --speculative_decoding_mode=draft_tokens_external ve --max_draft_len hedef model için belirtilmelidir.
trtllm-build
--checkpoint_dir ./ckpt-draft
--output_dir=./draft-engine
--gpt_attention_plugin float16
--workers 4
--gemm_plugin=fp8
--reduce_fusion disable
--use_paged_context_fmha=enable
--use_fused_mlp enable
--multiple_profiles enable
--max_batch_size=32
--max_num_tokens=8192
--max_seq_len=131072
trtllm-build
--checkpoint_dir=./ckpt-target-405b
--output_dir=./target-engine
--gpt_attention_plugin float16
--workers 4
--gemm_plugin=fp8
--use_paged_context_fmha=enable
--use_fused_mlp enable
--multiple_profiles enable
--max_batch_size=32
--max_num_tokens=8192
--max_seq_len=131072
--low_latency_gemm_plugin fp8
--speculative_decoding_mode=draft_tokens_external
--max_draft_len 10
# 70B hedef ve taslak modellerini 1 H200 üzerinde FP8 hassasiyetle derleme adımları
# FP8 kontrol noktalarını oluşturun
python3 quantization/quantize.py --model_dir --dtype float16 --qformat fp8 --kv_cache_dtype fp8 --output_dir /ckpt-draft --calib_size 512 --tp_size 1
python3 quantization/quantize.py --model_dir= --output_dir=./ckpt-target-70b --dtype=float16 --qformat fp8 --kv_cache_dtype fp8 --calib_size 512 --tp_size 1
# Derleme adımları
trtllm-build
--checkpoint_dir ./ckpt-draft
--output_dir=./draft-engine
--gpt_attention_plugin float16
--workers 1
--gemm_plugin=fp8
--reduce_fusion disable
--use_paged_context_fmha=enable
--use_fused_mlp enable
--multiple_profiles enable
--max_batch_size=32
--max_num_tokens=8192
--max_seq_len=131072
trtllm-build
--checkpoint_dir=./ckpt-target-70b
--output_dir=./target-engine
--gpt_attention_plugin float16
--workers 1
--gemm_plugin=fp8
--use_paged_context_fmha=enable
--use_fused_mlp enable
--multiple_profiles enable
--max_batch_size=32
--max_num_tokens=8192
--max_seq_len=131072
--low_latency_gemm_plugin fp8
--speculative_decoding_mode=draft_tokens_external
--max_draft_len 10
Son olarak, TensorRT-LLM’de spekülatif kodlamayı çalıştırın:
# Çıktı işle
# Önemli bayraklar: #--draft_engine_dir ve --engine_dir, taslak ve hedef motorları için belirtilmelidir.
# --draft_target_model_config, Taslak-Hedef Modelin yapılandırması ile ilgilidir. Örneğin, [4,[0],[1],False], draft_len=4, taslak modelin cihazı GPU0, hedef modelin cihazı GPU1 ve tokenların yerine logit kullanılması gerektiği anlamına gelir.
# Sadece CPP oturumu (düşük seviyeli API olarak yürütücü kullanarak) desteklenmektedir; Python oturumu (--use_py_session) desteklenmemektedir.
# 405B hedef model ile çalıştırma
mpirun -n 8 --allow-run-as-root python3 ./run.py
--tokenizer_dir
--draft_engine_dir ./draft-engine
--engine_dir ./target-engine
--draft_target_model_config = "[10,[0,1,2,3,4,5,6,7],[0,1,2,3,4,5,6,7], False]"
--kv_cache_free_gpu_memory_fraction=0.35
--max_output_len=1024
--kv_cache_enable_block_reuse
--input_text="İki dizide ortak elemanları bulmak için bir program yazın, herhangi bir ek veri yapısı kullanmadan."
# 70B hedef model ile çalıştırma
mpirun -n 1 --allow-run-as-root python3 ./run.py
--tokenizer_dir
--draft_engine_dir ./draft-engine
--engine_dir ./target-engine
--draft_target_model_config = "[10,[0,1,2,3,4,5,6,7],[0,1,2,3,4,5,6,7], False]"
--kv_cache_free_gpu_memory_fraction=0.35
--max_output_len=1024
--kv_cache_enable_block_reuse
--input_text="İki dizide ortak elemanları bulmak için bir program yazın, herhangi bir ek veri yapısı kullanmadan."
Spekülatif kodlama olmadan verim performansını benchmark yapmak için, aşağıdaki kod örneğindeki adımları izleyin:
# 405B modelini taslak model olmadan verim benchmark'ı çalıştırmaya
trtllm-build --checkpoint_dir ./ckpt-target-405b --output_dir /data/405B-TRT/ --gpt_attention_plugin float16 --workers 4 --max_batch_size 32 --max_seq_len 131072 --max_num_tokens 8192 --use_fused_mlp enable --reduce_fusion enable --use_paged_context_fmha enable --multiple_profiles enable --gemm_plugin fp8
python3 /app/tensorrt_llm/benchmarks/cpp/prepare_dataset.py --output token-norm-dist.json --tokenizer /llama-3_1-405b/ token-norm-dist --num-requests 1000 --input-mean 500 --input-stdev 0 --output-mean 200 --output-stdev 0 > /tmp/synthetic.txt
trtllm-bench --model latency --engine_dir /data/405b-TRT/ --dataset /tmp/synthetic.txt
# 70B modeli için aynı adımları, motor derleme sürecinde --workers 1 kullanarak tekrarlayın
TensorRT-LLM spekülatif kodlama ayrıca üretim uyumlu dağıtımlar için NVIDIA Triton Inference Server arka planda da desteklenmektedir.
Triton Inference Server, AI çıkarımını kolaylaştıran bir açık kaynaklı çıkarım sunma yazılımıdır. Triton TensorRT-LLM Arka Ucu ile performans ve işlevselliği artırmak için birçok farklı özellikten yararlanabilirsiniz:
Özet
TensorRT-LLM, farklı model mimarileri için büyük dil modellerini optimize etmek ve verimli bir şekilde çalıştırmak için çeşitli özellikler sunmaktadır. Daha düşük gecikme optimizasyonları ve iyileştirilmiş verim hakkında daha fazla bilgi almak için şu yazılara göz atabilirsiniz:
- Yüksek Hızda Çıkarım Bölüm 1: Medusa ile NVIDIA HGX H200 üzerinde %190 Daha Yüksek Llama 3.1 Performansı
- Yüksek Hızda Çıkarım Bölüm 2: Blackwell Geliyor. NVIDIA GH200 NVL32, NVLink Anahtarı ile İlk Token Performansında Büyük Bir Sıçrama Göstermektedir



