


Geniş dil modelleri (LLM’ler), çeşitli sektörlerde eşsiz fırsatlar yaratmaktadır. Ancak, bu modellerin araştırma ve geliştirme aşamalarından güvenilir, ölçeklenebilir ve sürdürülebilir üretim sistemlerine geçişi, kendine özgü operasyonel zorluklar sunmaktadır.
LLMOps, yani geniş dil modeli operasyonları, bu zorlukları aşmayı amaçlayan bir yaklaşımdır. Geleneksel makine öğrenimi operasyonları (MLOps) ilkelerini temel alarak, LLM yaşam döngüsünün yönetimi için bir çerçeve sunar; bu çerçeve verilerin hazırlanmasından model ince ayarına, dağıtımdan izlemeye ve sürekli iyileştirmeye kadar birçok aşamayı kapsar. LLM’lerin operasyonel hale getirilmesi, süreç ve dağıtım aşamalarında birçok önemli zorluğu da beraberinde getirir, bunlar arasında:
- İnce ayar süreci yönetimi: Büyük modellerin yönetilmesi, farklı hiperparametrelerle çok sayıda deneyin izlenmesi, sonuçların tekrar üretilebilirliğinin sağlanması ve dağıtık bilgisayar kaynaklarının verimli bir şekilde kullanılması gerekmektedir.
- Ölçekli değerlendirme: Ölçekli değerlendirmelerde, LLM çıktılarının subjektif kalitesini ve güvenliğini değerlendirmek için basit metriklerin ötesine geçmek zorunludur. Bu problem, her bir ajan-knotun bireysel performansını izole etmek ve değerlendirmek zordur ve bu da etkili büyük ölçekli analizlerin önünde büyük bir engel oluşturur.
- Model versiyonlama ve izleme: İnce ayar yapılmış modellerin kökenini, temel model versiyonunu, ince ayar verisini, hiperparametreleri ve değerlendirme sonuçlarını izlemek, tekrar üretilebilirlik, hata ayıklama ve düzenleyici uyumluluk için kritik önemdedir. Büyük model belgelerinin etkin bir şekilde yönetilmesi ve depolanması da zordur.
- Çıktı sunma karmaşıklığı: Düşük gecikme süresi ve yüksek verimlilik ile gerçek zamanlı çıkarım yapan LLM’lerin dağıtımı ve sunulması, özel sunum çerçeveleri, büyük modeller veya LoRA gibi teknikler için verimli model yükleme gerektirir ve talebe göre dinamik ölçekleme gerektirir. Farklı donanım yapılandırmaları arasında çıkarım performansını optimize etmek sürekli bir zorluktur.
Amdocs, telekomünikasyon çözümleri konusunda uzmanlaşmış bir firma olarak, özel LLM’lerini operasyonel hale getirmek ve AI girişimlerini hızlandırmak için bu zorlukları aşmaya çalışmaktadır. Amdocs, veri döngüleri oluşturmak için NVIDIA AI Blueprint kullanarak sağlam bir LLMOps pipeline’ı inşa etmiştir. Bu yapı, NVIDIA NeMo mikroservislerini kullanarak ince ayar, değerlendirme, güvenlik ve bunların NVIDIA NIM olarak verimli, ölçeklenebilir dağıtımını sağlamaktadır.
Bu benimseme, otomatik ve deklaratif yönetim için bulut tabanlı bir GitOps yaklaşımı tarafından yönlendirilmiştir. Bu blog yazısında, kullandıkları mimariyi derinlemesine inceleyeceğiz, bu yapının LLMOps zorluklarını nasıl aştığını göstereceğiz ve elde edilen sonuçları vurgulayacağız.
Amdocs’taki veri bilimci Liad Levi-Raz, “NVIDIA NeMo mikroservisleri ve GitOps ile yönetilen NVIDIA NIM yığınını kullanmak, LLM’lerle iterasyon yapma ve dağıtma yeteneğimizi köklü bir şekilde dönüştürdü. CI/CD otomasyon sistemimize entegre ettik, bu da yeni LLM’lerin hızlı ve verimli bir şekilde değerlendirilmesine olanak tanıyor.” şeklinde ifade etmiştir. “Veri bilimcisi olarak, yalnızca LLM ince ayarına odaklanabiliyorum ve altyapı detaylarıyla uğraşmak zorunda kalmıyorum.”
NVIDIA NeMo Mikroservisleri
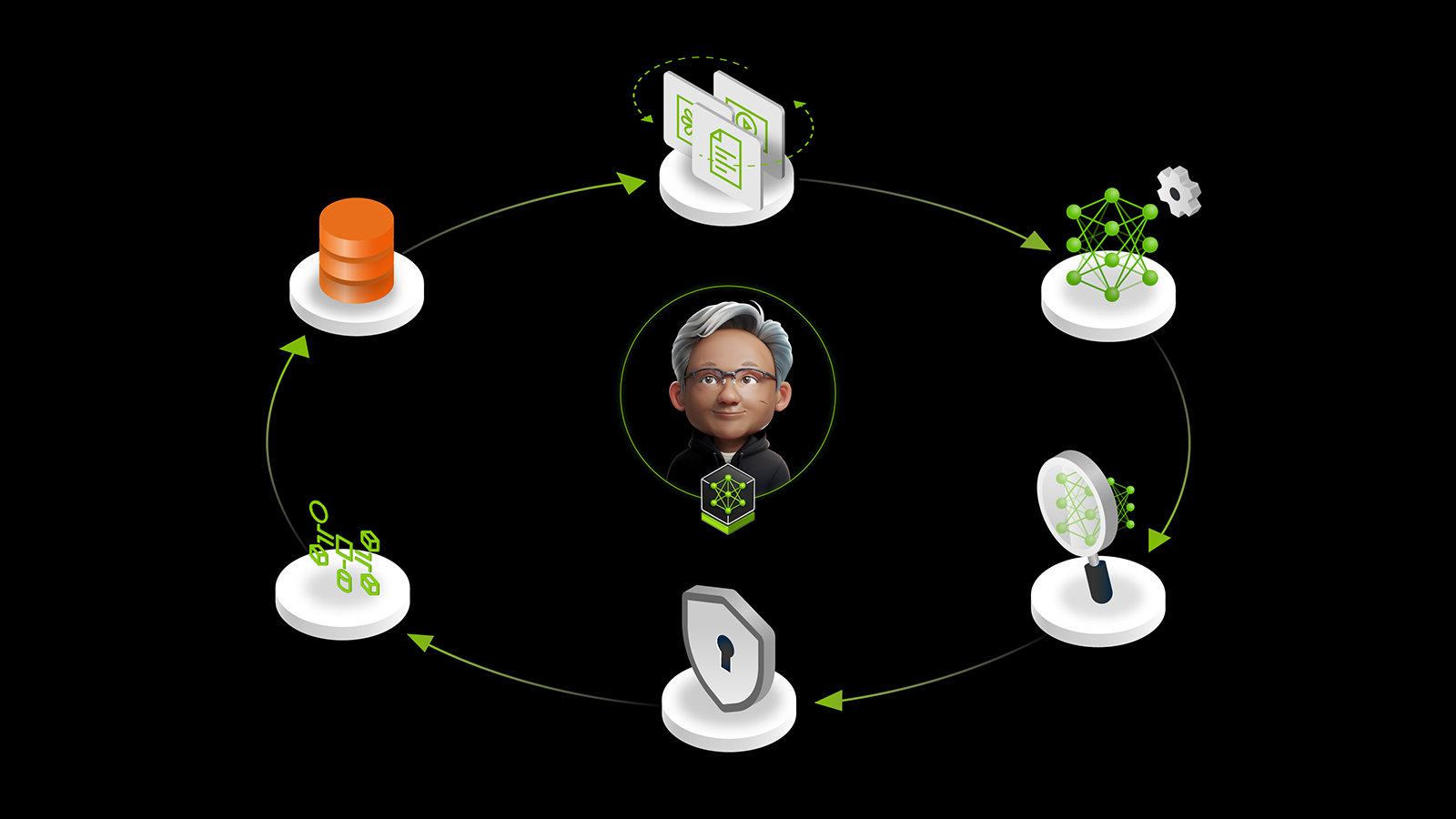
NVIDIA NeMo mikroservisleri, LLM’ler için sürekli bir iyileştirme döngüsünü kolaylaştırmak üzere tasarlanmıştır. Bu döngü, LLMOps’un yineleme niteliğini vurgulamak üzere bir “Kurumsal AI Döngüsü” olarak görselleştirilir. Bu döngü, dağıtım aşamasında elde edilen içgörülerin ve yeni verilerin geliştirme sürecine geri beslenmesini sağlayarak LLM’lerin performansını ve yeteneklerini sürekli olarak iyileştirir.
Bu döngü, veri döngüleri oluşturmak için NVIDIA AI Blueprint olarak adlandırılan referans mimarisi çerçevesinde inşa edilmiştir. Aşağıdaki diyagram, bu kavramı ve önemli NeMo mikroservislerinin içerisindeki rolünü göstermektedir.

Bu yineleme süreci, NeMo Curator tarafından işlenen kurumsal verilerle başlar. Hazırlanan veriler, NVIDIA NeMo Özelleştirici tarafından özelleştirilir ve NVIDIA NeMo Değerlendirici tarafından değerlendirilir. NeMo Guardrails, altındaki model kullanım olayı için bir güvenlik ve uyum katmanı sağlar.
Son olarak, model, ileri düzey çıkarımlar için NVIDIA NIM olarak dağıtılabilir. NVIDIA NIM, üretken AI modellerinin dağıtımını hızlandırmak ve basitleştirmek için tasarlanmıştır. Bu, bu modellerin standart Container mikroservisleri olarak paketlenmesini ve çıkarım performansını optimize etme yöntemini sağlar.
Vaka Çalışması: Amdocs amAIz GenAI Platformu
LLMOps zorluklarını aşmak için, özellikle yeni LLM’leri hızlı ve güvenilir bir şekilde doğrulamak amacıyla Amdocs, sağlam bir GitOps tabanlı LLMOps stratejisi benimsedi. Bu yaklaşım, NVIDIA AI Blueprint ile mevcut amAIz platformu ile doğrudan entegre edilmiştir. Bu, amAIz Suite için yeni LLM’ler üzerinde güçlü değerlendirme ve önemli regresyon testleri yapılmasına olanak tanımaktadır. LLM’nin yapılandırmasını sağlayarak, süreç—NVIDIA DGX Cloud’da çalışan bir Kubernetes kümesinde GPU bağımlı bileşenlerin dağıtımını da içeren—otomatik olarak tetiklenmektedir. Sonraki bölümde, GitOps tabanlı LLMOps pipeline’ını tanıtacağız.
GitOps Tabanlı LLMOps Metodolojisi
Bu bölüm, inşa edilen GitOps tabanlı LLMOps pipeline’ını detaylandırmakta ve göstermektedir. Şekil 2, oluşturulan LLMOps pipeline’ının yüksek seviyeli iş akış diyagramını göstermektedir. Diyagramın üst kısmında, Amdocs ortamında bulunan bileşenler, alt kısmında ise NVIDIA DGX Cloud‘da bulunan bileşenler yer almaktadır.

Amdocs ortamındaki bileşenler şunlardır:
- Git deposu: Değişikliklerin kaydedildiği ve veri bilimcilerin güncellemeleri gönderdiği tek kaynak olarak hizmet veren bir sürüm kontrol sistemi. ArgoCD, güncellemeleri çekmekte ve bunları izlemektedir.
- Yönetim Kubernetes kümesi: Amdocs içinde ana orkestra ortamı olan, ArgoCD ve Argo Workflow’yi barındıran bir Kubernetes kümesi. Bu Kubernetes kümesi, Azure Kubernetes Service (AKS) ile oluşturulmakta ve sadece CPU tabanlı hesaplama düğümleri içermektedir.
- ArgoCD: Kubernetes için sürekli dağıtım aracıdır. Sürekli olarak Git Deposu’nu değişiklikler için izler, değişiklikleri çeker ve Kubernetes Kümesini istenen durumu karşılayacak şekilde senkronize eder. Ayrıca GPU gerektiren mikroservislerin ve diğer bileşenlerin dağıtımını da tetikler.
- Argo Workflow: Kubernetes kümesinde çalışan, LLM iş akışlarını oluşturmak ve yürütmekten sorumlu bir iş akışı yürütme motorudur.
- LLM iş akış bileşenleri: LLM iş akışları için önceden tanımlanmış, yeniden kullanılabilir yapılar. Bu bileşenler, LLM iş akışları şablonları tarafından referans alınır. Argo İş Akışları’nın
ClusterWorkflowTemplatekaynağına dayanmaktadır.
LLM iş akış şablonları, Argo Workflow Template kaynaklarına dayanan, LLM görevleri için yeniden kullanılabilir şablonlardır. Bu şablonlar, LLM iş akışlarının yapısını ve sıra işlemlerini tanımlar. Bu şablonlar, belirli bir LLM iş akış bileşeni olan nemo-customization-template gibi bileşenleri birleştirerek LLM pipeline’ı oluşturur. Şekil 3, ince ayar işlemleri için bir LLM iş akışının yüksek seviyeli bir temsiliyi göstermektedir. Diyagramda her bir kutucuk, genel pipeline içindeki belirli bir görevi gerçekleştiren bir bileşeni temsil etmektedir.

NeMo mikroservislerinin dağıtımı, NVIDIA NIM’in yanı sıra ince ayar ve değerlendirme işlerinin yürütülmesi otomatik olarak NVIDIA DGX Cloud‘da gerçekleşir. Şekil 2’de gösterildiği gibi, Amdocs’un ArgoCD örneği ile DGX Cloud içerisinde çalışan özel olarak ayrılmış bir Kubernetes kümesiyle entegrasyon sağlanmaktadır. Bu kümede yönlendirilen gelen tüm istekler öncelikle bir geçit aracılığıyla geçer ve bu istekler daha sonra intelliganz bir şekilde veya Kubernetes ingress controller’a veya doğrudan Kube-API sunucusuna yönlendirilerek işlem görmektedir.
LLMOps Pipeline’ının İşleyişi
LLMOps pipeline’ı, veri setinin hazırlanmasıyla başlar. Telekomünikasyon sektörüne özel veriler, örneğin müşteri fatura verileri, yüklenir. Daha sonra bu veriler otomatik olarak biçimlendirilir ve eğitim ile test setlerine ayrılmaktadır. Veriler, dönüşümlere, anonimleştirmeye ve tokenizasyon işlemine tabi tutulur ve NVIDIA NeMo çerçeve yetenekleri kullanılarak sentetik olarak genişletilebilir.
Amdocs, bu kullanım durumu için etiketlenmiş bir veri setine ihtiyaç duymuştur. Amdocs, beklenen girdiler ve çıktılarla birlikte birçok örnek içeren kompakt bir eğitim veri seti oluşturmuştur. Tablo 1, örnek bir veri setini vurgulamaktadır.
| Çeşitli fatura başlıkları (girdiler) | Kullanıcı Sorusu | JSON Çıktısı | |
| 1 | [{‘id’: ‘amaiz_id_1300_10_27_24’, ‘fatura_tarihi’: ‘2024-10-19’, ‘faturalama_dönemi’: {‘başlangıç_tarihi’: ‘2023-10-27’, ‘bitiş_tarihi’: ‘2023-11-26’}, …}] | Faturamın neden artırıldığını fark ettim. Açıklayabilir misin? | {‘fatura_bulundu’: ‘true’, ‘fatura_id’: ‘amaiz_id_1300_11_27_24’, ‘fatura_tarihi’: ‘2024-11-19T17:33:00.000000’} |
| 2 | [{‘id’: ‘amaiz_id_9241_10_24_24’, ‘fatura_tarihi’: ‘2024-10-19’, ‘faturalama_dönemi’: {‘başlangıç_tarihi’: ‘2023-10-24’, ‘bitiş_tarihi’: ‘2023-11-23’}, ‘ödenecek_tutar’: …}] | Merhaba, neden faturam geçen aydan daha fazla?? Faturam Kasım’da $180.98’ken Aralık’ta $208.35 oldu. | {‘fatura_bulundu’: ‘false’} |
Veri seti, NVIDIA NeMo Veri Deposu‘na yüklenir. Ardından, pipeline yeni bir temel LLM olarak NIM (örneğin LLaMA 3.1 8B – instruct) olarak dağıtılmaktadır.
Daha sonra, parametre verimli ince ayarlama (PEFT) yöntemi kullanılarak, LoRA gibi, hazırlanan veri setinin bir alt kümesinde işlem gerçekleştirilir ve sonuçlanan model, NeMo Özelleştirici aracılığıyla NeMo Veri Deposu’na yüklenir.
Sonrasında, çok aşamalı bir değerlendirme süreci, NeMo Değerlendirici aracılığıyla tetiklenmektedir.
Bu aşamada, regresyon testleri yürütülerek hem temel hem de ince ayar yapılmış model, GSM8K, SQuAD, GLUE ve SuperGLUE gibi çeşitli standartlaştırılmış benchmark’lar kullanılarak değerlendirilir. Bu adım, yeni modelin genel yetenekleri olumsuz etkilenmediğini doğrulamak için kritik bir regresyon testidir.
Daha sonra, spesifik bir iş değerlendirmesi yapılır. Bu değerlendirme, temel ve ince ayar yapılmış modellerin tahminlerinin karşılaştırılması ve ilgili metrikler kullanılarak performans analizi yapılmasını içerir. Sonuçta, alan uzmanları en iyi performans gösteren modeller için nihai bir insan değerlendirmesi yapar ve iş gereksinimleriyle uyumlu olup olmadığını kontrol eder. Seçilen ince ayar yapılmış LoRA model adaptörü, LLM’ler için NVIDIA NIM ile dağıtılır.
Bu pipeline’da, Git, tek kaynak olarak hizmet vermektedir; veri bilimcileri LLM iş akışlarını kod olarak gönderirken, DevOps ekipleri altyapı yapılandırmalarını yönetmektedir. Bu süreç, Argo tarafından yönetilmektedir: ArgoCD, repertuarı sürekli izlerken, mikroservislerin Kubernetes üzerinde dağıtım ve senkronizasyonunu sağlarken, Argo Workflows, NVIDIA DGX Cloud üzerinde model ince ayarı ve değerlendirme gibi zorlu görevleri yerine getirmektedir. Bu, bilim insanlarının NeMo mikroservislerine API’ler aracılığıyla doğrudan bağlantı kurup etkileşimli bir şekilde deneme yapmasına da olanak tanır. Tam denetim sağlamak için, MLflow otomatik olarak deney metriğini yakalayarak entegre edilmiştir.
Bu entegre GitOps yaklaşımı, LLMOps pipeline’ı için güçlü ve otomatik bir orkestra katmanı sunarak, tüm yapılandırmaların ve iş akışı tanımlarının Git’te versiyonlandığı için tekrarlanabilirliği sağlamaktadır. Kullanıcılar, yeni modellerin performans bilgilerini ve uygunluklarını manuel müdahaleye ihtiyaç duymadan hızlı bir şekilde bulabilmektedir, bu da AI benimseme döngüsünü hızlandırmaktadır.
Sonuçlar
Değerlendirme sonuçları, ince ayar sürecinin birçok açıdan kayda değer faydalarını göstermektedir. Standart benchmark’lar olan TriviaQA kullanarak yapılan regresyon testleri, ince ayar yapılmış modelin temel becerileri koruduğunu doğrulamaktadır; bu model, 0.6’lık bir puanı, temel modelle eşleşerek elde etmiştir.
İnce ayar süreci, belirli bir görevde performans artışı sağlamış, LoRA ince ayar versiyonu için 0.83’lük bir doğruluk oranı elde edilirken; bu oran temel model olan 0.74‘lük puanın üzerinde yer almaktadır. Bu, yalnızca 50 eğitim örneği ile gerçekleştirilmiştir.

Bu iyileşme, nicel metriklerin ötesine geçmektedir. Nicel analiz, ince ayar yapılmış modelin doğru biçimlendirilmiş ve doğru sonuçlar üretmeyi öğrendiğini göstermektedir; örneğin, bir faturanın bulunmadığı durumları saptarken, temel model bu spesifik durumlarda başarısız olmuştur.

Daha derin, alanına özgü içgörüler elde etmek için değerlendirmede önemli bir bileşen, özel bir LLM-as-a-judge yaklaşımını sunmaktır. Bu yaklaşım, yanıtları insan tarafından oluşturulmuş referanslar ile karşılaştırmak için özel veri setleri ve KPİ (Anahtar Performans Göstergeleri) ile uyumlu olan metrikler kullanmaktadır. Bu, doğruluk, alaka düzey ve akıcılığı değerlendirmektedir.
Bu yöntemlerin esnekliği ve dayanıklılığı, çok yönlü değerlendirmeler için özelleştirilmiş bir alan sağlar. Bu gelişmiş teknik, otomatik benchmark’lar ve benzerlik metrikleri ile birleştirildiğinde kapsamlı bir performans görünümü sunar ve verilerin döngüsel olarak iyileştirilmesini sağlayarak ince ayar modelinin kalitesini sürekli olarak artırma döngüsünü oluşturur. Daha küçük modeller, hem performans hem de maliyet optimizasyonu sağlayarak üretim aşamasındaki iş akışlarına güç verebilir.
Sonuç
LLM’leri operasyonel hale getirmek önemli zorluklar sunmaktadır; özellikle pipeline karmaşıklığı, ölçekli dağıtım ve sürekli performans ile güvenliği sağlama konusunda. NVIDIA AI Blueprint kullanarak yapılandırılan mimarinin, sürekli fine-tuning ve değerlendirme için NVIDIA NeMo mikroservislerini, verimli çıkarım için NVIDIA NIM’i ve orkestra sağlamak için ArgoCD ve Argo Workflow’u içermesi, sağlam bir LLMOps pipeline’ı inşa etmeyi mümkün kılmaktadır. Bu yapı, otomatik iş akışlarını kolaylaştırır, bir veri döngüsü gibi sürekli iyileştirme döngülerine olanak tanır ve üretim ortamında LLM’leri yönetmenin karmaşıklıklarını doğrudan ele alır. Vaka çalışması, bu tür bir pipeline’ın mevcut CI/CD süreçlerine entegrasyonunun pratik faydalarını vurgulamaktadır.
Amdocs ve NVIDIA arasındaki iş birliği hakkında daha fazla bilgi edinin.
NVIDIA AI Blueprint ile veri döngülerine başlamanın ve AI destekli telekom operasyonlarını keşfetmenin yollarını inceleyin.



