


RAPIDS v24.10 Yayını
RAPIDS v24.10 yayını, veri bilimcileri ve geliştiricilere hızlandırılmış hesaplamayı sağlamak için önemli bir adım daha atıyor. Bu blog yazısı, yeni özellikleri vurgulamaktadır:
- Sıfır kod değişikliği ile hızlandırılmış NetworkX artık genel kullanımda (GA)
- Polars GPU motoru açık beta aşamasında
- Bölümden büyük GPU bellekli veri setlerinde UMAP desteği
- cuDF pandas ile NumPy ve PyArrow uyumluluğunun geliştirilmesi
- GPU’ların GitHub tabanlı CI sistemlerine entegrasyonuyla ilgili rehberler
- RAPIDS genelinde Python 3.12 ve NumPy 2.x desteği
Sıfır Kod Değişikliği ile Hızlandırılmış NetworkX
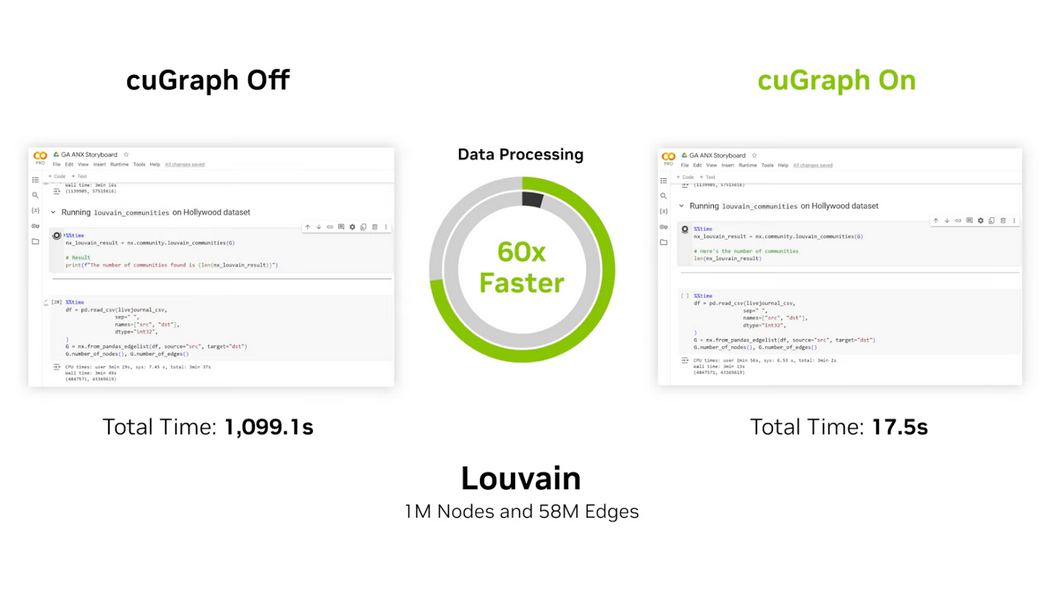
RAPIDS cuGraph ile hızlandırılmış NetworkX, 24.10 sürümünde NetworkX 3.4 ile genel kullanıma sunuldu. Bu sürüm, GPU hızlandırmalı grafik oluşturma, yeni bir kullanıcı deneyimi ve genişletilmiş belgeler ekliyor.
Hızlandırılmış grafik oluşturma, büyük grafiklerle çalışan iş akışları için son derece değerli olan %100 uçtan uca hızlandırma sağlar. CPU ve GPU arasında dönüşüm yapmak performansı azaltabileceğinden, bu özellik büyük veri setleri için önemlidir.
Tam uçtan uca hızlandırılmış NetworkX deneyimini, NX_CUGRAPH_AUTOCONFIG çevre değişkenini True olarak ayarlayarak etkinleştirebilirsiniz.
%env NX_CURGAPH_AUTOCONFIG=True
import pandas as pd
import networkx as nx
url = "https://data.rapids.ai/cugraph/datasets/cit-Patents.csv"
df = pd.read_csv(url, sep=" ", names=["src", "dst"], dtype="int32")
G = nx.from_pandas_edgelist(df, source="src", target="dst")
%time result = nx.betweenness_centrality(G, k=10)
Uçtan uca hızlandırma, betweenness merkeziyet, PageRank ve benzeri algoritmaları kullanan iş akışlarının büyük grafiklerde %10, %50 veya hatta %500 hızlanma deneyimlemesini sağlıyor.

Sıfır Kod Değişikliği ile Hızlandırılmış Polars Açık Beta
Eylül ayında cuDF destekli Polars GPU motoru açık beta aşamasında tanıtıldı. Kullanıcılar, GPU desteği ile sıfır kod değişikliği ile CPU’lara kıyasla %13’e kadar daha hızlı iş akışlarına erişebiliyor.

PDS-H benchmark ölçek faktörü 80 | GPU: NVIDIA H100 | CPU: Intel Xeon W9-3495X (Sapphire Rapids) | Depolama: Yerel NVMe. Not: PDS-H TPC-H’dan türetilmiştir ancak bu sonuçlar TPC-H sonuçları ile karşılaştırılamaz.
Polars, Lazy API’sine doğrudan entegre edilmiştir. Kullanıcılar, hesaplama tetiklendiğinde GPU’yı kullanmak için engine anahtar kelimesini collect ile birlikte kullanabilirler.
import polars as pl
df = pl.LazyFrame({"a": [1.242, 1.535]})
q = df.select(pl.col("a").round(1))
result = q.collect(engine="gpu")
Detaylı bilgi almak için NVIDIA ve Polars duyuru bloglarına göz atabilir ya da Polars GPU Desteği belgelerine dalabilirsiniz. Ayrıca bir Google Colab defterinde test edebilirsiniz.
Bölümden Büyük GPU Bellekli Veri Setlerinde UMAP Desteği
Sürüm 24.10 itibarıyla, cuML’nin UMAP algoritması, önceki sürümlerde bellek hatası veren büyük veri setlerini işleme yeteneğine sahip. Yenilikçi bir gruplama benzeri algoritma kullanarak ve gerektiğinde tam veri setini CPU belleğinde saklayarak, KNN grafiğini yalnızca GPU’da veri alt grupları işlenerek inşa edebiliyoruz.
Kullanıcılar, yeni isteğe bağlı işlevselliği nnd_n_clusters anahtar kelimesini 1’den büyük bir değer olarak ayarlayarak ve gerekli olduğunda data_on_host=True anahtar kelimesini fit veya fit_transform metoduna geçerek kullanabilirler.
from cuml.manifold import UMAP
import numpy as np
# Rastgele veri oluşturma
X = np.random.rand(n_samples, n_features).astype(np.float32)
# UMAP parametreleri
num_clusters = 4 # KNN Gruplama için küme sayısı
data_on_host = True # Verinin CPU'da saklanıp saklanmayacağı
# UMAP model yapılandırması
reducer = UMAP(
n_neighbors=10,
min_dist=0.01,
build_algo="nn_descent",
build_kwds={"nnd_n_clusters": num_clusters},
)
# Verileri fit et ve dönüştür
embeddings = reducer.fit_transform(X, data_on_host=data_on_host)
Kullanıcılar başlangıç değeri olarak kümelerin sayısını (örneğin, 4) ayarlayarak GPU bellek kullanımlarını yönetebilirler. Ancak, değeri çok yüksek ayarlamak, grafik oluşturma sırasında performans kaybına neden olabileceği için, veri setinin boyutuna ve mevcut GPU belleğine göre bir denge bulmak faydalı olabilir.
cuDF ile NumPy Uyumluluğunun İyileştirilmesi
cuDF’nin pandas hızlandırıcı modu artık tamamen NumPy dizileri ile uyumlu. Daha önce, isinstance denetimleri yapılırken cuDF pandas kullanıldığında NumPy dizileri için False dönerken, standart pandas kullanıldığında True dönebiliyordu. Bu, bazı kullanıcı iş akışlarının sorunsuz çalışması için türden tür dönüşümlerini gerektiriyordu.
24.10 sürümünden itibaren, cudf.pandas artık hızlandırıcı mod etkin olduğunda gerçek NumPy dizileri üretiyor. Örneğin:
%load_ext cudf.pandas
import pandas as pd
import numpy as np
arr = pd.Series([1, 2, 3]).values # artık gerçek bir numpy dizisi döner
isinstance(arr, np.ndarray) # True döner
Bu değişiklik, NumPy C API’sine dayanan kodların cuDF pandas ile sorunsuz çalışmasına olanak tanır.
Arrow Uyumluluğunun Geliştirilmesi
cuDF artık birçok PyArrow sürümünü destekliyor. Arrow uyumluluğu, cuDF kullanıcıları için uzun süredir zorluklar yaratan bir konu oldu. Şimdiye kadar cuDF’nin her sürümü, Arrow C++ API’sini kullandığı ve bu kullanımın getirdiği ikili uyumluluk gereksinimlerini karşılamak amacıyla belirli bir Arrow sürümüne bağlıydı.
Ancak bu sürümle birlikte, bu özellikler yalnızca Arrow C Veri Arayüzünü kullanacak şekilde yeniden yazıldı ve böylelikle Arrow C++ kullanımını tamamen durdurmuş olduk. Bu değişiklik sayesinde cuDF Python, artık PyArrow 14 ve sonrasındaki her sürümü destekleyebiliyor.
GitHub Tabanlı CI Sistemlerine GPU Entegrasyonu Rehberi
Topluluğumuzdan gelen geri dönüşlerde, GitHub tabanlı CI sistemlerine GPU entegrasyonunu kolayca sağlamanın zor olduğu bildirildi. Bu hedefle, yeni yönergeler RAPIDS Dağıtım belgelere eklendi ve bu, scikit-learn ekibinin deneyimlerine dayanmaktadır.
GitHub Actions, barındırılan GPU koşucularını desteklemektedir. Böylece GitHub’daki herhangi bir proje, CI iş yükleri için NVIDIA GPU’ları kullanarak test süreçlerini kolaylaştırabiliyor. Bu, projelerin RAPIDS kütüphaneleriyle entegre olmasını ve değişikliklerin uyumlu olup olmadığını test etmelerini büyük ölçüde kolaylaştırmaktadır.
GPU barındırılan koşucular, GitHub Action ücretsiz katmanının dahil olmadığını belirtmekte fayda var. GPU’lu koşucular genellikle dakika başına birkaç sent maliyet gerektirir ve projeler, maliyetleri kontrol altında tutmak için aylık harcama sınırı ekleyebilirler.
Bir GPU koşucusu ayarlamak için, GitHub organizasyon ayarlarının GitHub Actions bölümüne gidin ve yeni bir koşucu ekleyin. Ardından NVIDIA Ortak Görüntüsünü seçip, boyutu GPU destekli bir sanal makine olarak değiştirin.

Ardından iş akışlarınızı yeni koşucuları kullanacak şekilde yapılandırabilirsiniz.
name: GitHub Actions GPU Demo
run-name: ${{ github.actor }} GPU GitHub Actions denemesi yapıyor
on: [push]
jobs:
gpu-workflow:
runs-on: linux-nvidia-gpu
steps:
- name: GPU'nun mevcut olduğunu kontrol et
run: nvidia-smi
GitHub Actions GPU tabanlı iş akışlarının nasıl ayarlanacağı konusunda daha ayrıntılı bilgi için RAPIDS Dağıtım belgelerine göz atabilir ve GPU CI’nizi çalıştırmanın en iyi yöntemleri hakkında bilgi alabilirsiniz.
Scikit-learn projesi, GitHub Actions’ta GPU koşucuları kurarak, etiketler kullanarak belirli PR’larda GPU iş akışını manuel olarak tetiklemeyi başardı. Deneyimlerini öğrenmek için bu blog yazısına göz atabilirsiniz.
RAPIDS Platform Güncellemeleri
24.10 sürümünde RAPIDS paketleri, diğer bilimsel hesaplama yazılımlarıyla uyumlu hale getiren bazı önemli güncellemeler aldı. Paketler artık Python 3.10-3.12 ve NumPy 1.x ve 2.x ile kullanılabilir. Ayrıca, bu sürümle birlikte, conda-forge’da kullanılan fmt 11 ve spdlog 1.14 versiyonlarını desteklemektedir. Bu iyileştirmelerle birlikte, bu sürüm Python 3.9 veya NCCL 2.19’dan eski olanları desteklemeyi bırakmaktadır.
Sonuç
RAPIDS 24.10 sürümü, hızlandırılmış hesaplamayı veri bilimcilerine ve mühendislerine daha erişilebilir hale getirme misyonumuzda önemli bir adım daha atmıştır. Bu yeni yeteneklerle nelerin yapılacağını görmek için sabırsızlanıyoruz.
RAPIDS’e yeniyseniz, başlamak için bu kaynaklara göz atabilirsiniz.


