
UMAP, biyoinformatik, doğal dil işleme (NLP) konu modelleme ve makine öğrenimi ön işleme gibi alanlarda sıkça kullanılan bir boyut azaltma algoritmasıdır. Yüksek boyutlu veriyi daha düşük boyutlara gömmek için k-en yakın komşular (k-NN) grafiği oluşturarak, verilerin bulanık topolojik bir temsilini oluşturur.
RAPIDS cuML daha önce hızlandırılmış bir UMAP içeriyordu ancak bu yeni yazıda, performansı daha da artırmak için düşündüğümüz geliştirmeleri ortaya koyuyoruz.
Bu yazıda, RAPIDS cuML 24.10’da tanıtılan yeni özellikleri nasıl kullanabileceğimizi inceleyeceğiz. Ayrıca, NN-descent algoritması ve batching süreci hakkında detaylı bilgi vereceğiz. Son olarak, performans kazançlarını vurgulamak için benchmark sonuçlarını paylaşacağız.
Zorluklar
Karşılaştığımız zorluklardan biri, tüm komşular grafiği oluşturma aşamasının diğer aşamalara göre çok daha fazla zaman almasıydı.
cuML UMAP başlangıçta yalnızca bruteforce yaklaşımını kullanarak tüm komşular grafiğini oluşturuyordu. Bu, verisetindeki tüm vektörler üzerinde tam bir vektör araması yapmayı içerdiği için kötü ölçeklenebilirlik sorunlarına yol açıyordu.
Bruteforce, her vektör için her vektörle olan mesafeyi hesaplayarak çalıştığı için, zaman harcaması veri sayısı arttıkça kare şeklinde artıyor. 1M ve üzerindeki veri ölçeklerinde, tüm komşular grafiği oluşturma süresi %99 ve daha üzerinde bir zamana ulaşmakta.


Diğer bir zorluk ise, birçok cuML algoritması gibi, tüm verinin GPU hafızasına sığması gerekliliğiydi. Bu durum, yüzlerce GB olan büyük verisetleriyle başa çıkmayı zorlaştırıyordu. Örneğin, NVIDIA H100 GPU’nun 80 GB hafızası olsa bile, UMAP gibi algoritmalar, birçok küçük geçici hafıza tahsisi gerektirdiği için 80 GB’lık bir veriyi işlemek için yeterli olmayabiliyor.
UMAP’ı Hızlandırma ve Ölçekleme
Bu zorlukların üstesinden gelen yenilikçi bir batched yaklaşık komşu (ANN) algoritması geliştirdik. Bu, yaklaşık yöntemlerin hız için bazı doğruluk kayıpları anlamına geldiği durumlarda, genel bir algoritma kategorisine uygulanabilir.
ANN algoritmaları, en yakın komşuları bulmak için gereken mesafeleri hesaplamak için azaltmaya çalışarak, tüm komşular grafiği oluşturma sürecini hızlandırır. Bu yöntemle, büyük verisetlerini RAM hafızasına yerleştirip, yalnızca ihtiyaç duyulanları GPU hafızasına alabiliyoruz.
cuML 24.10’da UMAP, bu yeni yaklaşım sayesinde büyük verisetleri ile hızlı bir şekilde çalışabiliyor. Üstelik, varsayılan olarak etkin olduğu için kodunuzda herhangi bir değişiklik yapmanıza gerek kalmıyor!
| Matris boyutu | Brute-force ile UMAP çalıştırma | NN-descent ile UMAP çalıştırma |
| 1M x 960 | 214.4s | 9.9s (%21.6 hızlanma) |
| 8M x 384 | 2191.3s | 34.0s (%54.4 hızlanma) |
| 10M x 96 | 2170.8s | 53.4s (%40.6 hızlanma) |
| 20M x 384 | 38350.7s | 122.9s (%312 hızlanma) |
| 59M x 768 | Hafıza hatası | 575.1s |
Tablo 1, UMAP’ın artık bellek aşımlarını çalıştırmadığı durumlarda bile çalışabildiğini göstermektedir. Örneğin 50M noktalı bir verisetini GPU üzerinde çalıştırmak, daha önce 10 saatte yapılan işlemi sadece 2 dakikaya indiriyor.
Hızlı ve Ölçeklenebilir UMAP Kullanma
RAPIDS cuML 24.10 itibarıyla bu yeni özelliklerden yararlanmak için herhangi bir kod değişikliğine gerek yok. Ancak, daha fazla kontrol için, UMAP tahmincisi artık başlangıçta iki yeni parametre kabul ediyor:
build_algo: Tüm komşular grafiğini oluşturmak için kullanılacak algoritma. Aşağıdaki üç değerden biri olabilir:auto: Verisetinin boyutuna göre (50K’dan fazla verisample durumunda NN-descent kullanılır). Varsayılan değer.brute_force_knn: Tüm komşular grafiğini brute-force ile oluşturur.nn_descent: Tüm komşular grafiğini NN-descent ile oluşturur.
build_kwds: Tüm komşular grafiği oluşturma ile ilgili parametreleri geçirmek için Python sözlük tipi. Aşağıdaki parametreleri içerir:nnd_graph_degree: NN-descent ile k-NN oluştururken grafın derecesi. Varsayılan:64.nnd_intermediate_graph_degree: NN-descent ile k-NN oluştururken ara grafın derecesi. Varsayılan:128.nnd_max_iterations: NN-descent’te çalışacak maksimum iterasyon sayısı. Varsayılan:20.nnd_termination_threshold: NN-descent iterasyonlarının erken durması için sonlandırma eşiği. Varsayılan:0.0001.nnd_return_distances: NN-descent çıktısı mesafelerini döndürüp döndürmeyeceği. Bu, NN-descent ile UMAP’ı kullanmak için True olarak ayarlanmalıdır. Varsayılan:True.nnd_n_clusters: Kullanılan küme sayısı. Daha büyük bir sayı, büyük verisetleriyle çalışırken hafıza kullanımını azaltır. Varsayılan:2.nnd_do_batch: Batching içinTrueolarak ayarlanmalıdır. Varsayılan:False.
Ayrıca, verileri ana cihaz yerine host üzerinde tutma seçeneğiniz de mevcut. Bu data_on_host seçeneği, yalnızca build_algo=”nn_descent” ile uyumludur ve brute-force algoritması ile kullanılmamaktadır. Büyük verisetleri için batching algoritmasından en iyi şekilde yararlanmak için verilerin host üzerinde tutulması tavsiye edilir.
from cuml.manifold.umap import UMAP
data = generate_data()
# varsayılan olarak çalıştırma. 50K'dan fazla noktalar varsa NN Descent ile çalışır
umap = UMAP(n_neighbors=16)
emb = umap.fit_transform(data)
# açıkça yapılandırarak çalıştırma. Her zaman bu şekilde çalışır. Veri host üzerinde tutulabilir
umap = UMAP(n_neighbors=16, build_algo="nn_descent", build_kwds={"nnd_graph_degree": 32})
emb = umap.fit_transform(data, data_on_host=True)
# 4 küme ile batching NN Descent
umap = UMAP(n_neighbors=16, build_algo="nn_descent", build_kwds={"nnd_do_batch": True, "nnd_n_clusters": 4})
emb = umap.fit_transform(data, data_on_host=True)
Neden Yaklaşık Komşular?
Bruteforce, kesin ve kapsamlı bir algoritmadır. Aksine, yaklaşık algoritmalar kesin en yakın komşuları bulmayı garanti etmez, ama araştırma alanını verimli bir şekilde aleyhe yönlendirip, çok daha hızlı bir şekilde en yakın komşuları bulurlar. En yakın komşu inişi (NN-descent) olarak bilinen bu algoritma, doğrudan tüm komşular grafiğini yaklaşık olarak oluşturmak için kullanılıyor. Bu süreç, her veri noktası için rastgele en yakın komşuları başlatmayı ve ardından komşunun komşusunu keşfederek iteratif olarak en yakın komşu tahminlerini iyileştirmeye çalışır.
Orijinal çalışmada belirtildiği gibi, NN-descent “genellikle her noktayı, toplam veri kümesinin sadece birkaç yüzdesi ile karşılaştırarak %90’ın üstünde bir geri çağırma oranına ulaşır.” Kısacası, yaklaşık algoritmalar mesafe hesaplama gerekliliğini azaltma yolları bulur.
NN-descent, UMAP için tüm komşular grafiğini oluşturmak amacıyla NVIDIA cuVS kütüphanesinde uygulandı. Bu yöntem, büyük verisetleri için tüm komşular grafiği oluşturma sürecini yüzlerce kat hızlandırırken, işlevsel olarak eşdeğer sonuçlar da sağlar.
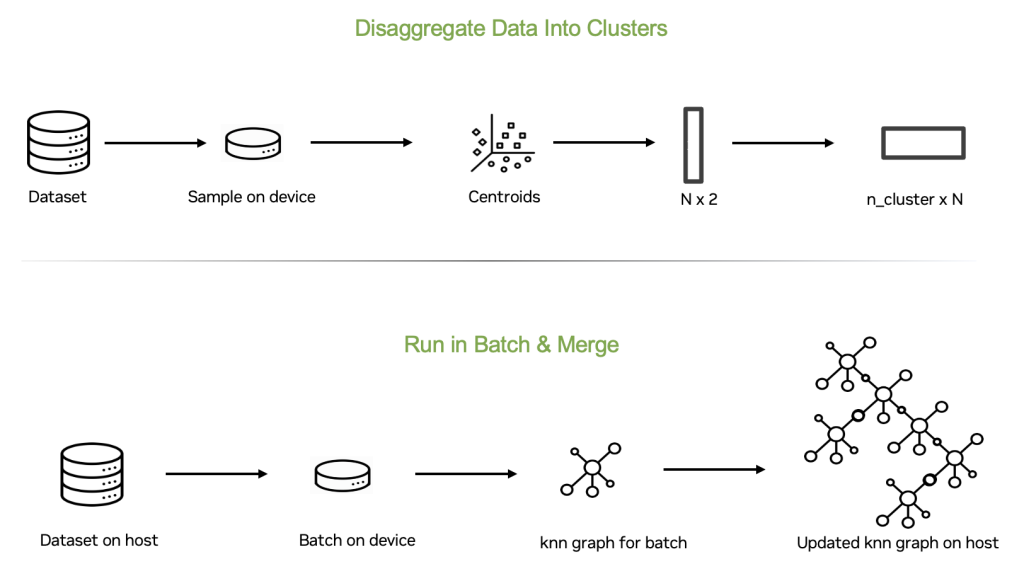
Batching Yöntemi ile Ölçeklenebilirlik
Büyük bir verisetini host üzerinde tutmak ve cihazda parça parça işlemek kolay görünebilir. Ancak, bir kümenin k-NN alt grafiklerini inşa etmek için yapılan her alt küme için benzer indekslere sahip verilerin birbirine yakın olması garanti edilmediği için ana zorluklar ortaya çıkar. Bu nedenle, veriseti, kesilen parçalar halinde işlenemez.
Bu sorunu aşmak amacıyla, popüler DiskANN algoritması üzerine şekillendirilmiş bir batching yöntemi geliştirdik. İlk olarak, hedeflenen küme sayısını belirlemek için veri kümesinin bir alt örneğini kullanarak dengeli bir k-means kümelemesi gerçekleştiriyoruz. Daha sonra, bu bilgiler kullanılarak veri kümesi, yakın küme merkezlerine dayanarak parçalara ayrılır.
Bu yaklaşım, her parçanın içindeki veri noktalarının birbirleriyle daha yakın olmasını sağlamakta ve en yakın komşuların aynı parçalar içinde bulunma olasılığını artırmaktadır. Bu bölüm, batching sürecinin her bir aşamasını detaylı bir şekilde açıklar:
- Kümeleri bulme
- Her küme için veri noktalarını bulma
- Küme veri noktalarının alt grafiklerini oluşturma
- Alt k-NN grafiğini global tüm komşular grafiği ile birleştirme
Kümeleri Bulma
Öncelikle, veri kümesinden küme merkezlerini çıkardık. Büyük veri kümesine sığmadığı varsayıldığından, verileri host hafızasında bırakarak cihazda tutabilecek yeterli bir örnek sunmak için rastgele bir alt küme seçtik. Genellikle, alt küme olarak verisetinin %10’unu almak yeterlidir.
Kullanıcı tarafından sağlanan nnd_n_clusters parametresi aracılığıyla, belirlenen küme sayısını tanımlamak için denge k-means ile örnek alt küme üzerinde işlem yaptık.
Veri Noktalarını Bulma
Sonraki adımda, her veri noktasının en yakın iki küre merkezini belirledik ve düzendikleri noktaları bulduk. Bu, her bir veri noktasının iki ayrı kümeye dahil edilmesini sağlayarak, nihai komşulukların yeterli sayıda komşuyu içermesi için bir önlem almış olduk.
Alt Grafikleri Oluşturma
Bütün bu bilgilerle belirlenen veri noktalarının altında alt grafikleri oluştururken, her bir kümeye ait veri noktalarına ulaşmanın ardından, GPU belleğinde bu veri parçalarını toplayarak, o parçalar için NN-descent algoritmasını uyguladık.
Global Grafi Birleştirme
Her bir küme için alt grafik oluşturulduktan sonra, bu k-NN alt grafi global tüm komşular grafiği ile birleştirildi. Bu süreç, ek bellek tahsisi gerektirmeden iki alt grafi birleştirmeyi sağlayan özel bir CUDA kernel kullanarak gerçekleştirildi.
Bu işlemler tamamlandıktan sonra, nihai sonuç olarak global tüm komşular grafiği edinildi. Bu grafik, başlangıç veri kümesinden çok daha küçük olduğu için, GPU belleğine güvenle aktarılabildi, bu da başlangıçta verisetinin belleğe sığmadığı durumlarda bile.
Performans Gelişmeleri
Bu bölümde, cuML UMAP ve yeni batched tüm komşular grafiği oluşturma yöntemi kullanılarak elde edilen performans etkisini değerlendiriyoruz.
Deneylerimizde, 80 GB bellekli bir NVIDIA H100 GPU kullandık. Karşılaştırmalar, GPU sürümündeki UMAP’ı temel alarak yapıldığı için bu hızlandırmalar yalnızca GPU iyileştirmelerinden kaynaklanmakta. Şekil 2, yeni NN-descent stratejisinin, brute-force tüm komşular grafiği oluşturan stratejiye göre toplam çalışma süresini nasıl etkilediğini göstermekte. 20M noktalı ve 384 boyutlu bir verisetinde, NN-descent kullanarak 311 kat hız kazanımı elde ederek, UMAP’ın toplam çalışma süresini 10 saatten 2 dakikaya indiriyoruz!


Şekil 3, bu önemli hız kazanımının UMAP gömme sonuçlarının kalitesini etkilemediğini göstermektedir. Kalite güvenilirliği puanları (mor renk ile gösterilmektedir) bunu doğrular. Güvenilirlik, 0 ile 1 arasında bir puandır ve düşük boyutlu UMAP gömme alanında yerel en yakın komşular yapısının ne kadar iyi korunduğunu gösterir.
Batching algoritmamızın sonuçların kalitesini koruduğunu belirtmek önemlidir. Şekil 3, işlenecek verilen sayısı arttıkça güvenilirlik puanlarında kayda değer bir değişiklik olmadığını ortaya koymaktadır.


Son olarak, 50M noktası ve 768 boyutu olan verisetinin GPU üzerinde çalıştırılabileceği sonucuna ulaşıyoruz, bu veriseti 150 GB boyutunda ve GPU belleği için fazlasıyla büyük. Batching algoritması, verisetini beş kümeye ayırarak bu başarıyı sağlıyor; oysa brute-force ile tüm komşular grafiği oluşturmaya çalışıldığında bellek hatası alınıyor.
Sonuç
Bunları duyurmanın heyecanını yaşıyoruz! UMAP’ın farklı alanlardaki yaygınlığı göz önüne alındığında, RAPIDS cuML’deki bu yeni özelliklerin, iş akışlarını önemli ölçüde hızlandıracağını ve bilgisayara dayalı bilim insanlarının büyük verisetleri ile elde edebileceği yeni içgörüler açığa çıkaracağından eminiz.
cuML ile başlamanız için conda ve pip paketlerinin yanı sıra hazır Docker konteynerlerini nasıl kuracağınızı öğrenmek için RAPIDS Kurulum Kılavuzu’na göz atmayı unutmayın.