Bu yılki Açık Veri Bilimi Konferansı (ODSC) Batı etkinliğinde yaklaşık 220 takım NVIDIA hackathonuna katılarak 24 saatlik makine öğrenimi (ML) yarışmasında kıyasıya mücadele verdi. Veri bilimciler ve mühendisler, çözümlerinin doğruluk ve işlem hızı açısından değerlendirilerek model tasarladılar. İlk üç takım, NVIDIA RTX Ada Nesil GPU’ları, Google Colab kredileri ve daha fazlasını içeren ödül paketlerini kazandılar. Bu başarıyı elde etmek için kazanan takımlar, RAPIDS Python API’lerini kullanarak en doğru ve performanslı çözümleri ortaya koydu.
ODSC’deki konuşmasında, Nick Becker, NVIDIA’nın RAPIDS AI ürün lead’ı, yapay zeka için hesaplama taleplerinin ve üretilen veri miktarlarının sürekli artmasının, veri işlemenin hızlandırılmış bilgisayarların yeni aşaması haline geldiğini vurguladı. Günümüzde günde yaklaşık 403 milyon terabayt veri üretiliyor; bu da veri merkezlerinin daha fazla veriyi daha verimli bir şekilde işlemesini gerektiriyor. Bu sayede daha yüksek doğruluk, güvenlik ve daha hızlı yanıt süreleri elde ediliyor.
Veri İşleme Genel Bakış
Şirketler, yapay zeka sistemlerini sonuca ulaştırmak ve optimize etmek için veri işleme darboğazlarını aşmak zorundalar. Hızlandırılmış bilgisayar uygulamaları, günümüzde giderek daha karmaşık hale gelen iş akışlarını daha verimli bir şekilde işlemeye olanak tanıyor.
Hackathon Yarışması ve Katılımcı Süreci
NVIDIA Hackathon yarışması, veri bilimcilerin hızla artan veri hacimleriyle başa çıkmalarını ve bunu GPU hızlandırması ile daha hızlı işlemelerini gösterdi. Katılımcılara yaklaşık 10 GB yapay tablo verisi sağlandı; bu veri 12 milyon konuyu içeriyor ve her biri 100’den fazla anonim özellik ile tanımlanıyor. Görevleri, hedef değişkeni (y) tahmin etmek ve kök ortalama kare hata (RMSE) ile en iyi sonuçları elde ederek doğruluk ve hız kazanmaktı. Sorunu çözmek ve çözümlerini optimize etmek için 24 saat süreleri vardı.
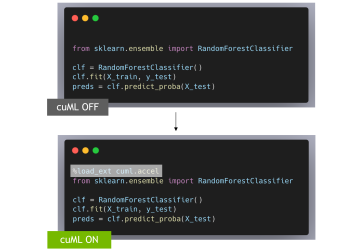
Katılımcılar, RAPIDS cuDF aracılığıyla pandas veya Polars’ı kullandı ve bazıları veri işleme ve model eğitimi için RAPIDS cuML veya XGBoost’tan yararlandı. Exploratory Data Analysis (EDA) ve özellik mühendisliği uygulamalarıyla birlikte birden fazla ML algoritmasının birleşimini uygulamaları teşvik edildi.
Hackathon Kazananlarından İpuçları
Bu yazıda, en iyi üç – Shyamal Shah, Feifan Liu ile ekip arkadaşları Himalaya Dua ve Sara Zare, Lorenzo Mondragon – kazananların içgörüleri ve stratejileri yer alıyor. Kendi sözleriyle, bu zorluğu nasıl ele aldıklarını ve en hızlı, en doğru çözümleri üretmeye ilişkin bazı ipuçlarını paylaşıyorlar.
Şampiyon Takımın Temel Stratejisi
Birincilik ödülünü kazanan Shyamal Shah, hackathon sırasında geniş bir tablodaki verileri analiz etme fırsatını yakaladığını belirtiyor. NVIDIA GPU’larının gücünden yararlanarak en iyi hesaplama verimliliği ve öngörü doğruluğu sağlamak için birkaç optimizasyon öngördü. Öncelikli olarak, NVIDIA RAPIDS ekosistemini kullanarak cuDF pandas uzantısını tercih etti. Detaylı özellik analizleri sonunda, normalleştirildiğinde 20 sayısal özelliğin etkili bir şekilde tekrarlandığını keşfetti. Bu bulgu, onun sadece bir temsil edici sayısal özellik olan “büyülü” kolonunu seçmesine yol açtı.
Yüksek kardinaliteye sahip kategorik değişkenler için, geleneksel bireysel kodlama yerine hedef ortalama kodlama ile şemayı sadeleştirdi. 106 özellikten sadece üç temel öngörücü seçerek eşzamanlı olarak işlem yükünü önemli ölçüde azalttı.
Sonuç: Shyamal, dikkatlice seçilmiş hiperparametre ayarlarıyla, modeli 1 dakika 47 saniye içinde eğitme ve tahmin etme süresine ulaştı. Bu deneyim, büyük veri setleri ile çalışırken GPU hıza dayalı işlem ile düşünceli özellik mühendisliği ve algoritma seçimlerinin nasıl birlikte kullanılabileceğini gösterdi.
İkinci ve Üçüncü Yarışmacıların Yöntemleri
İkincilik ödülünü kazanan Feifan Liu ve ekip arkadaşları Himalaya Dua ve Sara Zare, cuDF pandas’ın son derece verimli ve kullanımı kolay olduğuna dikkat çekti. Öncelikle, karmaşık veri ön işleme yöntemlerinden kaçınmayı önerdi. Kayıp değerleri -1 ile doğrudan atamak, yöneticilik ve verimlilik açısından etkili bir yaklaşım oldu. Ayrıca XGBoost’un CUDA desteğinden faydalanarak hızlandırılmış eğitim sağladılar.
Üçüncülük ödülünü kazanan Lorenzo Mondragon, RAPIDS ile GPU hızlandırmasını Polars ve pandas veri çerçevelerine entegre ederek verimliliği artırdı. Model için XGBoost kullanan Mondragon, hiperparametreleri dikkatlice ayarlayarak doğru bir sonuç elde etmeye odaklandı. Boş değerlerin doldurulması ve kategorik verilerin sıkıştırılmış biçimlerde kodlanması yöntemleri uygulandı.
Öneriler ve Kaynaklar
GPU hızlandırması büyük bir değişim yaratıyor. RAPIDS kullanımı, veri ön işleme ve model eğitim sürelerini önemli ölçüde azalttı; böylece büyük veri setlerini sıkı zaman kısıtları içinde işlemek mümkün hale geldi. Özellikle, veri bilimcilerin mevcut araçlarıyla sorunsuz bir şekilde entegre olabilmeleri büyük bir avantaj.
RAPIDS’i denemek isteyenler için bazı kaynaklar mevcut. cuDF pandas ve Polars ile ilgili başlangıç kılavuzları ve örnekler incelemek üzere bağlantıları kullanabilirsiniz. NVIDIA’nın web seminerini izleyebilir, özellik mühendisliği tekniklerini keşfedebilir ve bu alandaki en güncel kaynaklara ulaşabilirsiniz.