JSON, sistemler arasında etkileşim kurmak için yaygın olarak benimsenmiş bir format olup, özellikle web uygulamaları ve büyük dil modellerinde (LLM’ler) sıkça kullanılır. JSON formatı insan tarafından okunabilir olmasına rağmen, veri bilimi ve veri mühendisliği araçlarıyla işlenmesi oldukça karmaşıktır.
JSON verileri genellikle çoklu kayıtları temsil etmek için JSON Lines (ya da NDJSON) biçiminde ortaya çıkar. Veri işlemenin yaygın bir ilk adımı, JSON Lines verilerini bir veri çerçevesine (dataframe) okumaktır.
Bu yazıda, JSON Lines verilerini bir veri çerçevesine dönüştürmek için kullanılan Python API’lerinin performansını ve işlevselliğini şu kütüphaneler aracılığıyla karşılaştırıyoruz:
- pandas
- DuckDB
- pyarrow
- RAPIDS cuDF pandas Hızlandırıcı Modu
Özellikle karmaşık şemalara sahip veriler için cudf.pandas‘ın JSON okuyucusu ile iyi ölçeklenebilirlik ve yüksek veri işleme verimliliği gösterdiğini belgeliyoruz. Aynı zamanda, cuDF‘deki çok çeşitli JSON okuyucu seçeneklerinden bahsediyoruz; bu seçenekler, Apache Spark ile uyumluluğu artırmaya yardımcı olur ve Python kullanıcılarının alıntı normalizasyonu, geçersiz kayıtlar, karışık türler ve diğer JSON anormalliklerini ele almalarını sağlar.
JSON Ayrıştırma ve Okuma
JSON veri işleme söz konusu olduğunda, ayrıştırma ile okuma arasında bir ayrım yapmak önemlidir.
JSON Ayrıştırıcıları
JSON ayrıştırıcıları, örneğin simdjson, bir karakter veri tamponunu tokenlar vektörüne dönüştürür. Bu token’lar, JSON verisinin mantıksal bileşenlerini, yani alan adlarını, değerleri ve dizinin başlangıç/bitişini temsil eder. Ayrıştırma, JSON verisinden bilgi çıkarmak için kritik bir ilk adımdır ve yüksek ayrıştırma verimliliğine ulaşmak için önemli araştırmalar yapılmıştır.
JSON Lines’dan bilgi kullanmak için bu token’ların genellikle bir veri çerçevesine veya sütun tabanlı bir formata dönüştürülmesi gerekir; örneğin, Apache Arrow.
JSON Okuyucuları
JSON okuyucuları, örneğin pandas.read_json, girdi karakter verisini sütun ve satırlar olarak düzenlenmiş bir veri çerçevesine dönüştürür. Okuma süreci, bir ayrıştırma adımıyla başlar ve ardından kayıt sınırlarını tespit eder, üst düzey sütunları ve iç yapı veya liste çocuk sütunlarını yönetir, eksik ve null alanları ele alır, veri türlerini çıkarır ve daha fazlasını yapar.
JSON okuyucuları, yapısal olmayan karakter verilerini yapılandırılmış bir veri çerçevesine dönüştürerek JSON verilerini aşağı akış uygulamalarıyla uyumlu hale getirir.
JSON Lines Okuyucu Performans Testi
JSON Lines, veri temsil etmek için esnek bir formattır. JSON verisinin bazı önemli özellikleri şunlardır:
- Kayıt sayısı
- Üst düzey sütun sayısı
- Sütun başına yapı veya liste derinliği
- Değerlerin veri türleri
- String uzunluklarının dağılımı
- Eksik anahtarların oranı
Bu çalışmada, kayıt sayısını 200K olarak sabit tutup sütun sayısını 2’den 200’e kadar değiştirerek karmaşık şemaları inceledik. Kullanılan dört veri türü şunlardır:
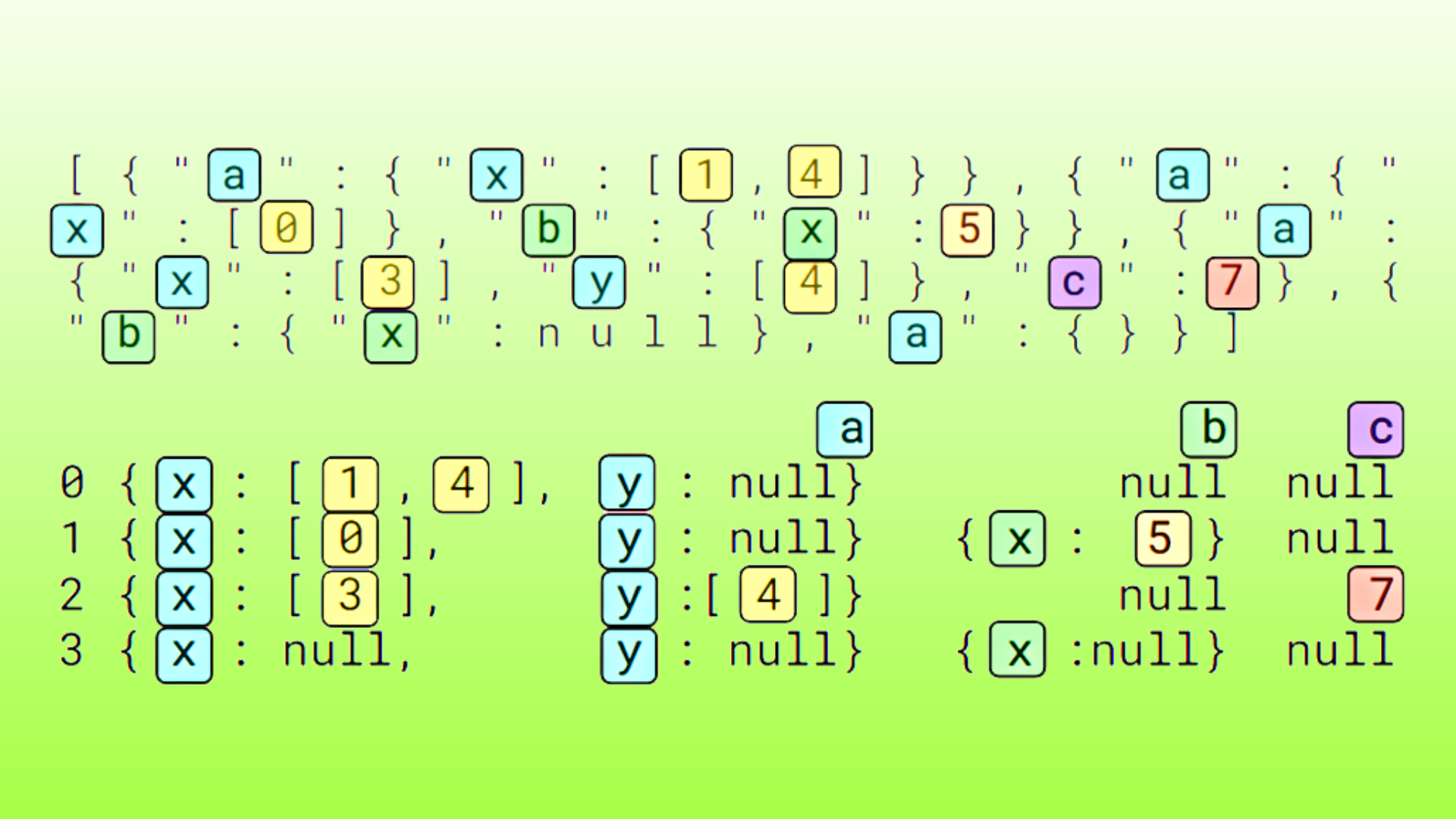
list<int>velist<str>içerikli iki çocuk öğe ilestruct<int>vestruct<str>içerikli bir çocuk öğe ile
Tablo 1, list<int>, list<str>, struct<int> ve struct<str> içindeki veri türlerinin ilk iki sütununu ve ilk iki kaydını göstermektedir.
| Veri türü | Örnek kayıtlar |
|---|---|
list<int> |
{"c0":[848377,848377],"c1":[164802,164802],...n{"c0":[732888,732888],"c1":[817331,817331],... |
list<str> |
{"c0":["FJéBCCBJD","FJéBCCBJD"],"c1":["CHJGGGGBé","CHJGGGGBé"],...n{"c0":["DFéGHFéFD","DFéGHFéFD"],"c1":["FDFJJCJCD","FDFJJCJCD"],... |
struct<int> |
{"c0":{"c0":361398},"c1":{"c0":772836},...n{"c0":{"c0":57414},"c1":{"c0":619350},... |
struct<str> |
{"c0":{"c0":"FBJGGCFGF"},"c1":{"c0":"ïâFFéâJéJ"},...n{"c0":{"c0":"éJFHDHGGC"},"c1":{"c0":"FDâBBCCBJ"},... |
Veri işleme istatistikleri, cuDF‘nin 25.02 sürümünde toplandı ve aşağıdaki kütüphane sürümleri kullanıldı: pandas 2.2.3, duckdb 1.1.3 ve pyarrow 17.0.0. Kullanılan donanım, bir NVIDIA H100 Tensor Core 80 GB HBM3 GPU ve Intel Xeon Platinum 8480CL CPU ile 2TiB RAM’den oluşuyordu. Zamanlamalar, üç tekrardan üçüncüsü toplanarak kaydedildi; bu, başlangıç gecikmesini önlemek ve girdi dosyası verisinin OS sayfa önbelleğinde mevcut olmasını sağlamak için gerçekleştirildi.
Ayrıca, hiçbir kod değişikliği gerektirmeyen cudf.pandas tasarımının yanı sıra, pylibcudf‘ten de performans verileri topladık. Pylibcudf, libcudf CUDA C++ hesaplama çekirdekli Python API’sıdır. Pylibcudf ile yapılan çalışmalarda, RAPIDS Bellek Yöneticisi (RMM) aracılığıyla CUDA async bellek kaynağı kullanıldı. Verim değerleri, JSONL girdi dosyası boyutu ve üçüncü tekrarın okuyucu çalışma süresi kullanılarak hesaplandı.
JSON Lines okuyucusunu çağırmak için çeşitli Python kütüphanelerinden birkaç örnek:
# pandas ve cudf.pandas
import pandas as pd
df = pd.read_json(file_path, lines=True)
# DuckDB
import duckdb
df = duckdb.read_json(file_path, format='newline_delimited')
# pyarrow
import pyarrow.json as paj
table = paj.read_json(file_path)
# pylibcudf
import pylibcudf as plc
s = plc.io.types.SourceInfo([file_path])
opt = plc.io.json.JsonReaderOptions.builder(s).lines(True).build()
df = plc.io.json.read_json(opt)
JSON Lines Okuyucu Performansı
Genel olarak, Python’daki JSON okuyucularının performansları arasında geniş bir aralık bulundu; toplam çalışma süreleri 1.5 saniyeden neredeyse 5 dakikaya kadar değişiklik gösterdi.
Tablo 2, toplam dosya boyutu 8.2 GB olan 28 girdi dosyasını işlerken yedi JSON okuyucu yapılandırmasının zamanlama verilerinin toplamını göstermektedir:
- JSON okumada cudf.pandas, koşulsuz olarak pandas‘a göre yaklaşık 133 kat hız artışı ve pyarrow motoru ile pandas’a göre 60 kat hız artışı gösterdi.
- DuckDB ve pyarrow da iyi performans sergileyerek sırasıyla 60 saniye ve 6.9 saniyelik toplam zaman ile sonuçlandı.
- En hızlı zaman ise 1.5 saniye ile pylibcudf‘dan geldi; bu,
block_sizeayarlamasıyla 4.6 kat hız artışı sağladı.
| Okuyucu Etiketi | Benchmark Süresi (sn) |
Yorum |
| cudf.pandas | 2.1 | -m cudf.pandas kullanarak komut satırından |
| pylibcudf | 1.5 | |
| pandas | 281 | |
| pandas-pa | 130 | pyarrow motorunu kullanarak |
| DuckDB | 62.9 | |
| pyarrow | 15.2 | |
| pyarrow-20MB | 6.9 | 20 MB block_size değeri kullanarak |
Tablo 2, girdi sütun sayılarını 2, 5, 10, 20, 50, 100 ve 200 olarak göstermekte ve veri türlerini list<int>, list<str>, struct<int> ve struct<str> ile sınırlamaktadır.
Veri türlerine ve sütun sayısına odaklandığımızda, JSON okuma performansının, kullanılan veri işleme kütüphanesine bağlı olarak geniş bir aralıkta değiştiğini gözlemledik; CPU tabanlı kütüphaneler için 40 MB/s ile 3 GB/s arasında performans, GPU tabanlı cuDF için ise 2–6 GB/s arasında bir verimlilik elde edildi.
Görsel 1, 200K satır ve 2–200 sütun sayısı için girdi boyutuna bağlı olarak veri işleme verimliliğini göstermektedir. Girdi dosyası boyutları yaklaşık 10 MB ile 1.5 GB arasında değişiklik göstermektedir.

Görsel 1’de, her alt grafikte girdi sütunlarının veri türleri yer almakta. Dosya boyutuna dair notasyonlar x eksenine yerleştirilmiştir.
cudf.pandas kullanımı ile read_json için 2–5 GB/s verimlilik kaydedildi. Bu verimlilik, sütun sayısı ve girdi veri boyutu ile birlikte artış göstermektedir. Ayrıca, sütun veri türlerinin verimlilik üzerinde önemli bir etkisi olmadığı gözlemlenmiştir. Pylibcudf kütüphanesi, cuDF-python’a göre 1-2 GB/s daha fazla verimlilik sunarak Python ve pandas üzerindeki önemli yükü azaltmaktadır.
Öte yandan pandasread_json kullanımında, varsayılan UltraJSON motoru (etiket “pandas-uj” olarak görülebilir) ile yüzde 40-50 MB/s verimlilik elde edilmiştir. Pyarrow motorunun (engine="pyarrow") kullanılması ise bu verimliliği 70-100 MB/s aralığına çıkartmıştır; ancak pandas JSON okuyucu performansı, her bir tablodaki öğeler için Python liste ve sözlük nesneleri oluşturma gereği nedeniyle sınırlı kalmıştır.
DuckDB read_json ile list<str> ve struct<str> işleme için 0.5–1 GB/s verimliliği bulunurken, list<int> ve struct<int> için 0.2 GB/s’den daha düşük değerler elde edilmiştir. Veri işleme verimliliği, sütun sayıları aralığında sabit kalmıştır.
Pyarrow read_json ile 5-20 sütunlar arasında 2-3 GB/s verimliliği elde edilmiş, sütun sayısı arttıkça verimlilik değerlerinin düştüğü gözlemlenmiştir. Veri türünün, okuyucu performansı üzerinde sütun sayısı ve girdi veri boyutundan daha az etkili olduğu belirlenmiştir. 200 sütun sayısında ve kayıt boyutu yaklaşık 5 KB olan satırlarda, verimlilik yaklaşık 0.6 GB/s’ye düşmektedir.
Pyarrow okuyucusunun block_size ayarını 20 MB artırmak, 100 veya daha fazla sütun sayısı için verimliliği artırırken, 50 veya daha az sütun sayısında verimliliği düşürmüştür.
Özetle, DuckDB sadece veri türlerine göre verimlilik değişkenliği gösterirken, cuDF ve pyarrow temel olarak sütun sayısı ve girdi veri boyutuna bağlı olarak performans değişikliğine sahiptir. GPU tabanlı cudf.pandas ve pylibcudf, karmaşık liste ve yapı şemaları için ve özellikle girdi veri boyutları 50 MB’tan fazlaysa en yüksek veri işleme verimliliğini göstermektedir.
JSON Lines Okuyucu Seçenekleri
JSON formatının metin tabanlı doğası gereği, JSON verileri genellikle geçersiz JSON kayıtları veya veri çerçevesine çok iyi uymayan anormallikler içerir. Bu tür JSON anormalliklerinin bazıları, tek tırnakla alınmış alanlar, kesilmiş veya bozulmuş kayıtlar ve karışık yapı veya liste türleridir. Bu tür durumlar veri akışını bozabilir.
Aşağıda bazı JSON anormalliklerine örnekler verilmiştir:
# 'Tek tırnaklı alan'
# "a" alan adı tek tırnak kullanıyor
s = '{"a":0}n{'a':0}n{"a":0}n'
# 'Geçersiz kayıtlar'
# ikinci kayıt geçersiz
s = '{"a":0}n{"a"n{"a":0}n'
# 'Karışık türler'
# "a" sütunu liste ile harita arasında geçiş yapıyor
s = '{"a":[0]}n{"a":[0]}n{"a":{"b":0}}n'
cuDF’deki gelişmiş JSON okuyucu seçeneklerini kullanmak için, cuDF-Python (import cudf) ve pylibcudf‘yi iş akışınıza dahil etmenizi öneririz. Verilerinizde tek tırnaklı alan adları veya string değerleri varsa, cuDF, bunları çift tırnaklara normalleştirmek için bir okuyucu seçeneği sunar. cuDF, Apache Spark ile uyumluluk sağlamak amacıyla allowSingleQuotes seçeneğini varsayılan olarak destekler.
Eğer verilerinizde geçersiz kayıtlar varsa, cuDF ve DuckDB, bu kayıtları null ile değiştirme seçenekleri sunar. Hata işleme etkinleştirildiğinde, bir kayıt ayrıştırma hatası ürettiğinde, ilgili satırdaki tüm sütunlar null olarak işaretlenir.
Bir alanda aynı isimle karışık liste ve yapı değerleri varsa, cuDF veri türünü dize olarak zorlamak için bir tür şeması aşma seçeneği sunar. DuckDB benzer bir yaklaşım sergileyerek JSON veri türünü çıkarır. Pandas ise karışık türler için muhtemelen en sadık yaklaşımı benimseyerek, girdi verilerini temsil etmek için Python liste ve sözlük nesnelerini kullanır.
Aşağıda cuDF-Python ve pylibcudf içinde, dikkat çekici bazı okuyucu seçenekleri ve “a” sütunu için tür şeması aşması içeren bir örnek bulunmaktadır. Daha fazla bilgi için cudf.read_json ve pylibcudf.io.json.read_json‘a bakabilirsiniz.
# cuDF-python
import cudf
df = cudf.read_json(
file_path,
dtype={"a":str},
on_bad_lines='recover',
lines=True,
normalize_single_quotes=True
)
# pylibcudf
import pylibcudf as plc
s = plc.io.types.SourceInfo([file_path])
opt = (
plc.io.json.JsonReaderOptions.builder(s)
.lines(True)
.dtypes([("a",plc.types.DataType(plc.types.TypeId.STRING), [])])
.recovery_mode(plc.io.types.JSONRecoveryMode.RECOVER_WITH_NULL)
.normalize_single_quotes(True)
.build()
)
df = plc.io.json.read_json(opt)
Tablo 3, birkaç yaygın JSON anomalisine yönelik Python API’leri kullanarak bazı JSON okuyucularının davranışlarını özetlemektedir. Çarpılar, okuyucu işlevinin bir istisna oluşturduğu; onay işaretleri ise kütüphanenin başarıyla bir veri çerçevesi döndürdüğü anlamına gelmektedir. Bu sonuçlar, kütüphanelerin gelecekteki sürümlerinde değişebilir.
| Tek Tırnak Kullanımı | Geçersiz Kayıtlar | Karışık Türler | |
| cuDF-Python, pylibcudf | ✔️ Çift tırnağa dönüştürme | ✔️ Null ile değiştirme | ✔️ String olarak temsil |
| pandas | ❌ İstisna | ❌ İstisna | ✔️ Python nesnesi olarak temsil |
pandas (engine="pyarrow) |
❌ İstisna | ❌ İstisna | ❌ İstisna |
| DuckDB | ❌ İstisna | ✔️ Null ile değiştirme | ✔️ JSON benzeri tip ile temsil |
| pyarrow | ❌ İstisna | ❌ İstisna | ❌ İstisna |
cuDF, Apache Spark konvansiyonlarıyla uyumlu olabilen birkaç ek JSON okuyucu seçeneği sunmaktadır ve bu seçenekler Python kullanıcıları için de kullanılabilir hale gelmiştir. Bu seçenekler arasında şunlar bulunmaktadır:
- Sayılar ve stringler için doğrulama kuralları
- Özel kayıt ayırıcıları
- Veri tipi sağlanan şemaya göre sütun budama
- NaN değerlerinin özelleştirilmesi
Daha fazla bilgi için, json_reader_options üzerine libcudf C++ API belgelerine başvurabilirsiniz.
Çok sayıda daha küçük JSON Lines dosyalarını etkin bir şekilde işlemek için çoklu kaynak okuma veya büyük JSON Lines dosyalarını parçalara ayırma desteği hakkında daha fazla bilgi için GPU hızlandırmalı JSON Veri İşleme başlığındaki RAPIDS belgelerini gözden geçirin.
Özet
RAPIDS cuDF, Python’da JSON verileriyle çalışmak için güçlü, esnek ve hızlandırılmış araçlar sunmaktadır.
Ayrıca, GPU hızlandırmalı JSON veri işleme RAPIDS Apache Spark için Hızlandırıcı ile de mümkündür; bu, 24.12 sürümünde başlayacaktır. Daha fazla bilgi için, Apache Spark üzerinde GPU hızlandırmalı JSON işleme hakkında bilgi edinin.
Daha fazla bilgi edinmek için aşağıdaki kaynaklara göz atabilirsiniz:
- cuDF belgeleri
- /rapidsai/cudf GitHub deposu
- RAPIDS Docker konteynerleri (sürekli sürümler ve gecelik derlemeler için mevcut)
- Veri Bilimi İş Akışlarını Hızlandırmak için Sıfır Kod Değişikliği DLI Kursu
- cuDF.pandas Profiler’ı GPU Hızlandırma için Kullanma